BookBrainz: JSON Web API
Personal information
Name: Akhilesh Kumar
IRC Nick: akhilesh
MB username: mastcoder
Email: akhileshnithcse@gmail.com
Github: akhilesh26
LinkedIn: Akhilesh Kumar
Time Zone. UTC+05:30
Proposal
Project overview
The project is aimed to design and implement the JSON API to programmatically query the BookBrainz database. Since the existing backend of BookBrainz website is written using node.js and its framework express.js, therefore we will also use the node.js and express.js to implement this project. This API will use the current BookBrainz ORM bookbrainz-data-js to access the database.
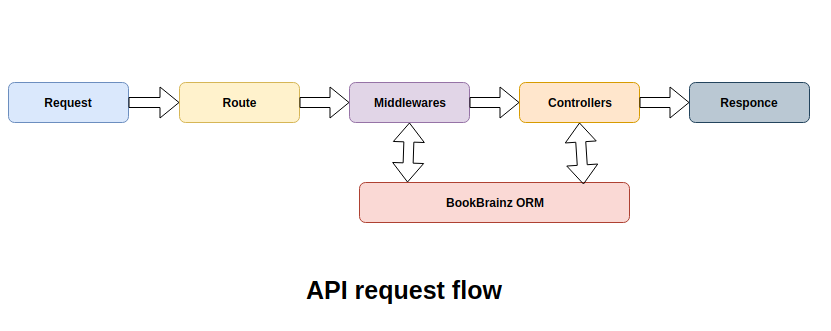
The API implementation code will be written in the bookbrainz-site repository. Many of the functions and database queries are written at src/server will also be required at src/api. To reuse common functions and database queries at src/api, we will move the common code at src/common. As the API progresses, the duplicate code will accordingly move to src/common.
The structure of the src directory would be as follows:
src/client: It contains client-side code base.
src/server: It contains the server-side code for the website.
src/api: This will include the API service related code base.
src/common: This will include common code base which will be used in both server and API.
test/api: All tests of API service will be written in this directory.
The URL structure of API will be harmonized with that of MusicBrainz API.
We will follow the Test-driven development process in which tests will be written using Mocha and Chai and then endpoints will be implemented in accordance to pass these tests.

The additional modules that will also be required for the API service are as follows:
-
Rate limiting: This module will also be required for API service to limit the number of requests that clients can make in a given period of time. We will use third party express library to implement this module.
-
Caching: This module is required to store frequently accessed data to reduce the response time of the server. It would be implemented using redis.
List of data that will be provided by API
There are 5 entity resources in our data model - work, edition, edition-group, author, publisher.
For each entity resource, we will handle three different GET requests:
lookup: /<ENTITY>/<BBID> or /<ENTITY>/<BBID>/<LINKED_INFO>
browse: /<ENTITY>?<LINKED_ENTITY>=<BBID>&limit=<LIMIT>&offset=<OFFSET>&<FILTER_PARAMS>
search: /search?query=<QUERY>type=<ENTITY_TYPE>&limit=<LIMIT>&offset=<OFFSET>
Since this would be a JSON API, there is no need to pass any parameter specifying the format of data.
Lookup request data
We will get basic information of entity by using BBID of that entity with /<ENTITY>/<BBID> like endpoints. If we will need linked information of any entity, like aliases, identifiers or relationships then we will use /<ENTITY>/<BBID>/<LINKED_INFO> like endpoints.
Browse request data
Here we will get the entity or list of entities by using the BBID of the directly linked entity. We can also pass some filter parameter to filter the entity. For example return list of works which is in any edition(use edition bbid) and type = short story.
We can use limit (optional) in case of a big list and offset (optional) to use in pagination.
Search request data
We will get the search result on the basis of query and type. Search is over either all entities or any specific entity. We can use limit(optional) and offset here also.
Project plan and implementation
API endpoints
The API will provide 5 resources, namely Work, Edition, Edition-Group, Author, Publisher, which represent core entities in our database.
Here we will use REST to design endpoints. I am mentioning some endpoints below. I aim at extending these endpoints for all types of entities and also accept changes as per the requirements of the community.
Root URL of API service will be https://api.bookbrainz.org/v2/
Lookup request endpoints
To get the data of each entity we will follow the endpoint format same as /<ENTITY>/<BBID> for basic information or /<ENTITY>/<BBID>/<LINKED_INFO> for linked information.
<ENTITY> <LINKED_INFO>
/work aliases, identifiers, relationships
/edition aliases, identifiers, relationships, author-credits
/edition-group aliases, identifiers, relationships, author-credits
/author aliases, identifiers, relationships
/publisher aliases, identifiers, relationships
GET /work
To get the information of work, we will send the GET request at the below URLs.
For basic detail:
URL: <ROOT_URL>/work/ba446064-90a5-447b-abe5-139be547da2e
Output will look like this:
{
"bbid": "ba446064-90a5-447b-abe5-139be547da2e",
"default-alias": {
"name": "Harry Potter",
"sort-name": "Harry Potter",
"alias-language": "English"
},
"languages": ["English"],
"disambiguation": "Harry Potter",
"type": "Epic"
}
For linked detail
To get the linked detail of any entity, we will send the GET request at the below URL. If we want more than one extra property we will need to make separate requests for each.
URL: <ROOT_URL>/work/ba446064-90a5-447b-abe5-139be547da2e/aliases
Output will look like this:
{
"aliases" : [
{
"name": "Hard Times",
"sortName": "Hard Times",
"alias-language": "English",
primary: true
},
{
"name": "Hard Times – For These Times",
"sort-name": "Hard Times – For These Times",
"alias-language": "English",
primary: false
}
]
}
URL: <ROOT_URL>/work/ba446064-90a5-447b-abe5-139be547da2e/identifiers
Output will look like this:
{
"identifiers": [
{"type": "LibraryThing Work", "value" : "10090"},
{"type": "Wikidata ID", "value" : "Q1340493"}
]
}
GET /edition
To get the inforamation of edition, We will send the GET request at the below URL.
For basic detail
URL: <ROOT_URL>/edition/b401d9a7-f1bd-4bcd-a394-7c336d2f3a0b
Output will look like this:
{
"bbid": "b401d9a7-f1bd-4bcd-a394-7c336d2f3a0b",
"default-alias": {
"name": "Harry Potter and the Philosopher's Stone",
"sort-name": "Potter, Harry and Philosopher's Stone, the",
"alias-language": "English"
},
"languages": ["English","Hindi"],
"disambiguation": "Illustrated Edition",
"edition-format": "Hardcover",
"hight": 267,
"width": 270,
"pages": 256,
"weight": 100,
"staus": "offial",
"relese-date": "2015-10-06",
"edition-group": {
"bbid": "360ebc31-3961-43bb-b533-ed2a7882231b",
"default-alias": {
"name": "Harry Potter and the Philosopher’s Stone",
"sort-name": "Harry Potter and the Philosopher’s Stone",
"alias-language": "English"
}
},
"publisher": {
"bbid": "d30d7df9-eb6f-4bd5-a69f-a9a3362a6f4a",
"default-alias": {
"name": "Bloomsbury",
"sort-name": "Bloomsbury",
"alias-language": "English"
}
}
}
Here also we can use /<ENTITY>/<BBID>/<LINKED_INFO> to get linked inforamation of that entity. Refer to the GET /work example mentioned earlier.
GET /edition-group
To get the inforamation of edition-group, We will send the GET request at the below URL.
URL: <ROOT_URL>/edition-group/360ebc31-3961-43bb-b533-ed2a7882231b
{
"bbid": "b401d9a7-f1bd-4bcd-a394-7c336d2f3a0b",
"default-alias": {
"name": "Harry Potter and the Philosopher's Stone",
"sort-name": "Potter, Harry and Philosopher's Stone, the",
"alias-language": "English"
},
"disambiguation": null,
"type": "Book"
}
Here also we can use /<ENTITY>/<BBID>/<LINKED_INFO> to get linked inforamation of that entity. Refer to the GET /work example mentioned earlier.
GET /author
To get the inforamation of author, We will send the GET request at the below URL.
URL: <ROOT_URL>/author/8f3d202f-fa37-4b71-9e81-652db0f8b83d
Output will look like this:
{
"bbid": "8f3d202f-fa37-4b71-9e81-652db0f8b83d",
"default-alias": {
"name": "J. K. Rowling",
"sort-name": "Rowling, J. K.",
"alias-language": "English"
},
"disambiguation": null,
"type": "Persion",
"gender": "Male",
"date-of-birth": "1965-07-31",
"place-of-birth": "United Kingdom",
"ended": "false",
"date-of-death": null,
"place-of-death": null
}
Here also we can use /<ENTITY>/<BBID>/<LINKED_INFO> to get linked inforamation of that entity. Refer to the GET /work example mentioned earlier.
GET /publisher
To get the inforamation of publisher, We will send the GET request at the below URL.
URL: <ROOT_URL>/publisher/d30d7df9-eb6f-4bd5-a69f-a9a3362a6f4a
Output will look like this:
{
"bbid": "d30d7df9-eb6f-4bd5-a69f-a9a3362a6f4a",
"default-alias": {
"name": "Bloomsbury",
"sort-name": "Bloomsbury",
"alias-language": "English"
},
"type": "Publisher",
"area": "United Kingdom",
"date-founded": "1986-09-26",
"date-dissolve": null
}
Here also we can use /<ENTITY>/<BBID>/<LINKED_INFO> to get linked inforamation of that entity. Refer to the GET /work example mentioned earlier.
Browse request endpoints
Browse requests are a direct lookup of all the entities which are directly linked to another entity.
<ROOT_URL>/<ENTITY>?<LINKED_ENTITY>=<BBID>&limit=<LIMIT>&offset=<OFFSET>&<FILTER_PARAMS>
The default value of limit is 5 and offset is 0. The offset will be used for pagination.
For example:
URL: https://api.bookbrainz.org/v2/work?author=14fcaca2-7380-4272-846a-c8dc5f539b33&limit10&offset=0
This URL will return 10 works of the author whose bbid is 14fcaca2-7380-4272-846a-c8dc5f539b33. In this URL, work is an entity which is to be browsed, and, the author is the linked entity.
Linked Entities list
The following list shows which entity you can browse using linked entities.
<ENTITY> <LINKED_ENTITY>
/work edition, author
/edition work, author, edition-group, publisher
/edition-group edition, author
/author work, edition
/publisher edition, work
Filter parameters
The following list shows filter parameters that will be used to browse the entity.
<ENTITY> <FILTER_PARAMS>
/work type, language
/edition status, language
/edition-group type
/author type
/publisher type, area
Browse example for work: GET /work?author=BBID
Here we will get list works related to an author using the author’s bbid. We will follow the same design to browse all five entity resources. Currently, there are no author-credits for work, so, we will be using relationships to fetch works of an author. Whereas, for edition and edition-group, we will use author-credits.
Filter parameters
type=short-story: Returned works should be short story type.
lang=eng: Returned works should be in English. Value of lang parameter should be three characters ISO 639 code.
URL: <ROOT_URL>/work?author=ac59097e-7f86-436d-9308-f6e63871ceff&type=short-story&lang=eng&limit=2
Output response data
{
"work-offset": 0,
"work-count": 5,
"works": [
{
"bbid": "0da7b366-8505-481a-b355-41312015861a",
"default-alias": {
"name": "The Shadow Out of Time",
"short-name": "Shadow Out of Time, The",
"alias-language": "English"
},
"disambiguation": null,
"type": "Short Story",
"language": "English"
},
{
"bbid": "378a6ee2-688d-4d0a-8693-de4c1e562f39",
"default-alias": {
"name": "The Haunter of the Dark",
"short-name": "Haunter of the Dark, The",
"alias-language": "English"
},
"disambiguation": null,
"type": "Short Story",
"language": "English"
}
]
}
Search request endpoints
Search functionality will be implemented on the elasticsearch engine which currently used in the website.
<ROOT_URL>/search?q={search query}&type={entity_type}&limit={number}&offset={number}
To search over all type of entity we will use type=all-types and if we want to search over some specific type, then we’ll give that entity type. For example, we’ll use type=edition to search over editions. The type parameter is optional with a default value of all-types. limit and offset will also be optional parameters, with default values of 15 and 0 respectively. The offset will be used for pagination.
GET /search?q=QUERY
Examples
URL: <ROOT_URL>/search?q=dark&limit=4
Search result over all entities.
{
"search-count": 50,
"search-results": [
{
"bbid": "f0dffc49-3122-4224-b862-aabbfe816217",
"entity-type": "Work",
"default-alias": {
"name": "In a Dark, Dark Wood",
"sort-name": "In a Dark, Dark Wood",
"alias-language": "English"
}
},
{
"bbid": "30763369-3134-4a73-83d4-a1a6a6637a5c",
"entity-type": "Edition,
"default-alias": {
"name": "Forest dark",
"sort-name": "Forest dark",
"alias-language": "English"
}
},
{
"bbid": "a8deab8d-7be8-4836-8a7d-c1223c7f7bf9",
"entity-type": "author",
"default-alias": {
"name": "Amma Darko",
"sort-name": "Amma Darko",
"alias-language": "English"
}
}
]
}
URL: <ROOT_URL>/search?q=dark&type=edition&limit=1
Search result over editions.
{
"seach-count": 10,
"search-results": [
{
"bbid": "30763369-3134-4a73-83d4-a1a6a6637a5c",
"entity-type": "Edition,
"default-alias": {
"name": "Forest dark",
"sort-name": "Forest dark",
"alias-language": "English"
}
}
]
}
These endpoints are not finalized and I am hoping for the discussion on these during the community bonding period to finalize the API spec before actual coding starts.
Status Codes
These are some standard status codes for responses which we will use.
200 OK – success
400 Bad Request – invalid request
429 Forbidden – rate limit exceeded
404 Not Found – value not found
Rate limiting module
We will implement a rate limit module for our API Service, which limits the number of requests that clients can make in a given period of time. The rate at which the client IP address is making requests will be measured.
This module will be required for the API service because BookBrainz has finite resources and wishes to make the database available to as much of the Internet community as possible.
To implement this module we will use third party middleware Express Rate Limit.
For example, to limit the maximum number of search requests to 20 per minute for every client IP, we can do that as follows.
const rateLimit = require("express-rate-limit");
app.enable("trust proxy");
const searchLimiter = rateLimit({
windowMs: 60 * 1000, // 1 minutes
max: 20,
message: "Too many search requests from this IP"
});
app.use("/search", searchLimiter);
Caching module
Caching will be managed by using redis. This module will also be used for caching query results for the website server.
As shown in the below diagram when the server gets a GET request from the client, first check if the required result is present in the cache, if yes, then it will return that to the client[step-1 green lines]. Otherwise, a query will be sent to the database or the ElasticSearch and this response will be updated in the cache then the server responds to the client[step-2 then step-3 blue lines].
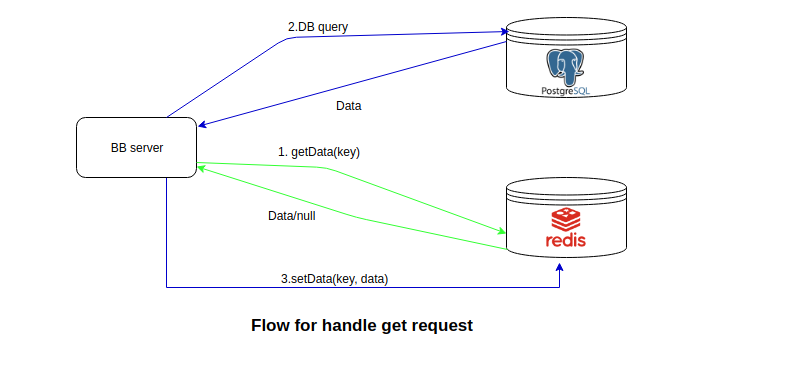
If the server gets POST request then first update the database, once database successfully updated then save/update the cache of that entity and invalidate the cache of entities that referenced with the updated entity. It will follow the flow shown below in the diagram:

-
Implementation
- I will implement a generateKey function similar to gen_key for generating cache keys. For example, the key for a lookup request will be generated using a function call as given below.
generateKey('lookup', entityType, bbid)- Our main focus will implement a cache module for handling lookup requests properly at SoC time. After that, we will extend it to all type of requests.
-
Cache invalidation:
As mention in the above section, for POST requests we are updating the cache anyways. Therefore, at any point in time, we will have updated data in the cache.
To avoid cache overflow, We will configure the Redis with maxmemory configuration directivemaxmemory <size_in_mb>and if the maxmemory limit is reached we will be usingallkeys-lru(evict keys by trying to remove the less recently used (LRU) keys first, in order to make space for the new data added) as eviction policy as given here in detail.
I also propose to add a TTL(time to live) field for every cached result. We can set TTL value to 24 hours(this value is used in CB for example).
Documentation:
The complete documentation of API code, as well as API, will be required in this project. At the time of coding, we will use JSDoc to document the code. Once one endpoint has been implemented then we will document that endpoint for public use at BookBrainz User Guid with examples of request URLs and output data.
GUI update
Once all work related to API will be finished then add a new page in BookBrainz website showing basic details of API service and important links.
Optional Idea
Authentication module
We will implement an authentication module for the API service. Client authentication will be required for GET request as well as user authentication, will be required to process POST requests.
-
Client Authentication:
- The client id and client secret that we get while creating an application in MusicBrainz, are used as authentication parameters for this module to identify the clients.
- Client send these parameters in request header to BookBrainz API server, API server send these parameters to MusicBrainz OAuth, then MusicBrainz authenticate that client and send the response back to BB API server, then we process the request and send the response back to the client(BB API user) accordingly.
-
User Authentication
- Client will send the user token to BB API server with the POST request. BB API server sends this user token to MusicBrainz to authenticate that token. MusicBrainz sends the response back to BB API server then BB API server will process that request accordingly.
Proposed Timeline
A broad timeline of the work to be done is as follows:
Community Bonding (May 06 - May 27):
In this time, our main focus will be to get last year’s data import project merged into the master branch. It would add a lot of data to BookBrainz database.
I will spend some time learning about test-driven development using frameworks like chai and mocha. I will focus on formalizing coding and design decisions with the mentor to make sure that no bad decisions are made early in the process.
Here is a more detailed week-by-week timeline of the 13 weeks GSoC coding period (27 May - 19 August) to keep me on track:
-
Week 1 (May 27 - June 2):
- Begin with setting up the environment, upgrade the repository structure as explained in the project description.
- Write test and implement endpoint for
workentity to handlelookuprequest. This would require moving the already implemented functions and database queries tosrc/common
-
Week 2 (June 3 - June 9):
- Implement the cache module and use it to ensure that above endpoints work properly.
-
Week 3 (June 10 - June 16):
- Write test and implement endpoint for
editionandedition-groupentities to handlelookuprequest. This would also require moving the already implemented functions and database queries tosrc/common.
- Write test and implement endpoint for
-
Week 4 (June 17 - June 23):
- Write test and implement endpoint for
authorandpublisherentities to handlelookuprequest. This would also require moving the already implemented functions and database queries tosrc/common.
First evaluations here
- Write test and implement endpoint for
-
Week 5 (June 24 - June 30):
- Write test and implement endpoint for
workentity to handlebrowserequest. This would also require moving the already implemented functions and database queries tosrc/common.
- Write test and implement endpoint for
-
Week 6 (July 01 - July 07):
- Write test and implement endpoint for
editionandedition-groupentities to handlebrowserequest. This would also require moving the already implemented functions and database queries tosrc/common.
- Write test and implement endpoint for
-
Week 7 (July 08 - July 14):
- Write test and implement endpoint for
authorandpublisherentities to handlebrowserequest. This would also require moving the already implemented functions and database queries tosrc/common.
- Write test and implement endpoint for
-
Week 8 (July 15 - July 21):
- Work for the second evaluation by fixing bugs and cleaning up the code. Take reviews from the mentor and make relevant changes in code written so far.
Second evaluations here
-
Week 9 (July 22 - July 28):
- Write test and implement endpoint for
searchrequest. This would also require moving the already implemented functions and database queries tosrc/common.
- Write test and implement endpoint for
-
Week 10 (July 29 - August 04):
- Implement the rate limiting module and set the different limits to all type of endpoint. Limit we be discussed with mentor and community.
-
Week 11 (August 05 - August 11):
- Add a new page in BookBrainz website showing basic details of API service and important links
-
Week 12 (August 12 - August 18):
- If proposed endpoints’ implementation, caching and documentation is complete as per the schedule, I will be implementing API authentication module.
-
Week 13 (August 19 - August 26):
- Work for final submission and make sure that everything works. For example manual testing of all endpoints with different edge cases. Resolve the issues if found.
-
After Summer of Code
Continue working on BookBrainz. Resolving issues on this project reported by API users.
Move the focus to collect Books data from the open data libraries and other available sources.
Detailed Information About Me
I am a postgraduate computer science student at the National Institute of Technology, Hamirpur, India. I came across BookBrainz when one of my friends told me that MetaBrainz organization has a project based on awesome technologies like Node.js, React and ElasticSearch. I was interested in these technologies and had prior experience working on them too. So, from Nov 2017, I started reading BookBrainz’s code base and contributing to it. Here is a list of my pull requests. I have learned many new things from the MetaBrainz community. 
Question: Tell us about the computer(s) you have available for working on your SoC project!
Answer: I have a DELL laptop with an Intel i5 processor and 8 GB RAM, running Linux Mint.
Question: When did you first start programming?
Answer: I started programming in high school writing small C++ programs. Started programming in web design technologies as a freshman in college.
Question: What type of books do you read?
Answer: Mostly non-fiction biographies like Biography of Mahatma Gandhi, Narendra Modi : A Political Biography and Jyotipunj . I have also read some fiction from Chetan Bhagat like - Five Point Someone and One night at the Call Center.
Question: What aspects of the project you’re applying for (e.g., MusicBrainz, BookBrainz, etc.) interest you the most?
Answer: BookBrainz interests me since I really like the idea of keeping data open and free for public use. The project can be developed so as to have a publically accessible dump of literature data, which will expand over time with more editors and the data dump can also be used to create efficient book recommendation engines to serve a large community of worldwide readers.
Question: Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
Answer: I have worked on a bunch of personal projects that I have open-sourced like CSMS, Agricultural App and Connect2Roots.
Question: What sorts of programming projects have you worked on?
Answer: During last summer(2018), I interned at Cogoport and I worked as a front-end developer in referral program of Cogoport. I used React, styled-component and Next.js for server-side rendering. I used Google Charts for visualization of data in the dashboard.
During summers of 2017, I interned at IIT Bombay and worked on a project for creating a database of Temples of India, my work involved creating a site to interface with the data - search for the temple, edit temple information, comment and rate on temple’s page. I wrote frontend and backend from scratch, UI using ReactJS and backend in Node.js using Express framework. I wrote the search functionality by querying ElasticSearch database. I also worked on a Co-operative Society Management System, a desktop application to manage accounts, loans, and transactions in a co-operative bank. The project was written in Python, creating GUI using Qt5 and MySQL for the database which was interfaced by SQLAlchemy. When I was learning Java, I created a basic shop inventory system for learning the fundamentals.
Question: How much time do you have available, and how would you plan to use it?
Answer: During 10-20 May, I will be busy because of my semester exams and thesis submission, but I will still try to participate in IRC.
I am absolutely free after 20th May and can work full time (45-50 hrs per week) on the project until the final submission.
Question: Do you plan to have a job or study during the summer in conjunction with Summer of Code?
Answer: None, if selected for GSoC.
