Personal information
Name: Akhilesh Kumar
IRC Nick: akhilesh
MB username: mastcoder
Email: akhilesh5991@gmail.com
Github: akhilesh26
LinkedIn: Akhilesh Kumar
Time Zone. UTC+05:30
Proposal
Project overview
Presently, BookBrainz is in the process of migrating from Python server-side code to Node.js, due to this the web API needs to be rewritten. It will implement all the endpoints in the current API and also add some new endpoints as discussed by the community.
The Current Python API uses SQLAlchemy to interface with the database, which is based on an earlier schema which is not being currently used. The new API will use the current BookBrainz ORM bookbrainz-data-js which is written node to access the database. The older API uses OAuth, which I aim to replace with user authentication based on user tokens as is already used in ListenBrainz and client authentication will be implemented via a Kong plugin (key-auth). There was no rate-limiting feature in the earlier API, which will now be implemented via Kong(rate-limit) in my implementation. The server-side code will use koa.js (a Node.js server framework). We will use Test-driven development process in which tests will be written using Mocha and Chai and then endpoints will be implemented in accordance to pass these tests.
The Whole project is divided into two parts:
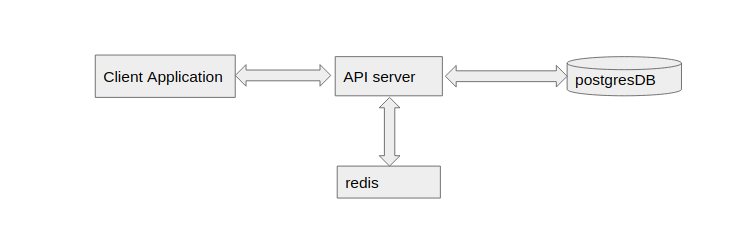
Part One: We implement all the endpoints with caching and tests are also written in this part. The client application communicates to the API server directly. API server manages the requests by using both Redis and the database.
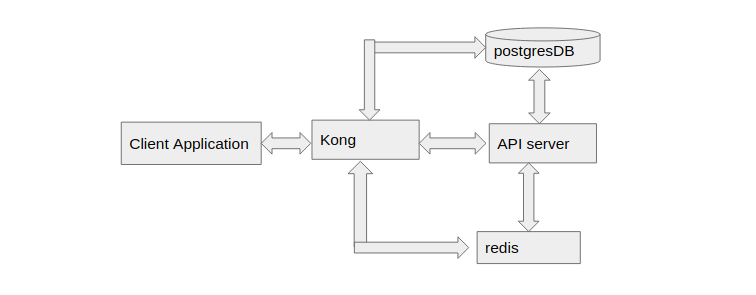
Part Two: In this part, we will upgrade the project by implementing key-auth and rate limiting through Kong as discussed above. Kong acts as a middleware server between the client application and API server. The Kong policies involved in the API should be decided by the community.
Deliverable goals to this proposal
- Add an application page which will show editor’s
user tokenandcreate applicationfunctionality to create an application and generate API-key. - The user will be able to refresh the token and get a new token, which is used to authenticate the user.
- The user will be able to create an application, edit the application details and also delete the application.
- The user will be able to create multiple applications.
- Implement all endpoints with request types- GET, POST, PUT, DELETE for all types of entities - publication, edition, work, creator, publisher.However, the DELETE request feature is subject to discussion by the community.
- Provide all information about the editor.
- Search will be also provided through the API with search over specific entity type.
- A cache module will be also implemented to manage the cache data with namespacing and cache invalidate functionality.
- The Client will be authenticated by using key-auth using Kong. User authentication is required for the requests wanting to modify the database.
- Rate limiting will be also implemented using Kong.
- The anonymous client will have only read accesses with a low rate-limit. Complete features would be provided only upon authentication.
List of data provided by API
This list will be upgraded according to requirements of the community.
Project plan and implementation
Basic setup
- Create a koa project directory for BookBrainz-ws and install all dependencies.
- Using the BB schema, create a database.
- Load dumps of the data into this database.
- Include the BookBrainz-data package which will be used to access data from the database.
- Install and set up the Kong server.
Basic outline of project structure:
├── package.json
├── config
│ └── config.js
├── src
│ └── server
│ ├── db
│ │ ├── connection.js
│ │ ├── queries
│ │ │ ├──publication.js
│ │ │ ├──edition.js
│ │ │ ├──work.js
│ │ │ ├──creator.js
│ │ │ ├──publisher.js
│ │ │ ├──search.js
│ │ │ └── editor.js
│ │ └── seeds
│ │ └── for all entities
│ ├── index.js
│ └── routes
│ ├── index.js
│ └── route files
└── test
| ├── routes.index.test.js
| └── test files for all routes
├── all other required files like .gitignore, .eslintrc.js
Updates in Schema and GUI
Implementing the authentication and rate limiting features will require some updates on existing database schema and GUI of the BookBrainz web interface.
Updates in schema
In the BookBrainz schema, a new table application will be added with the columns - application_name, homepage_url, description, editor_id, consumer_id, api_key. The first three columns are for basic information while the last three are the requirements of Kong. In Kong, we will use editor_id to generate api_key and consumer_id, api_key will be used for the purpose of client authentication and consumer_id will be used for rate-limiting. A user_token column will be added to the pre-existing editor table for user authentication, user_token will generate automatically for all editor.

Required updates in GUI
Some updates in the GUI of BookBrainz have to be made so as to add views that allow users to create an application and to display the user token.
Add a menu entry
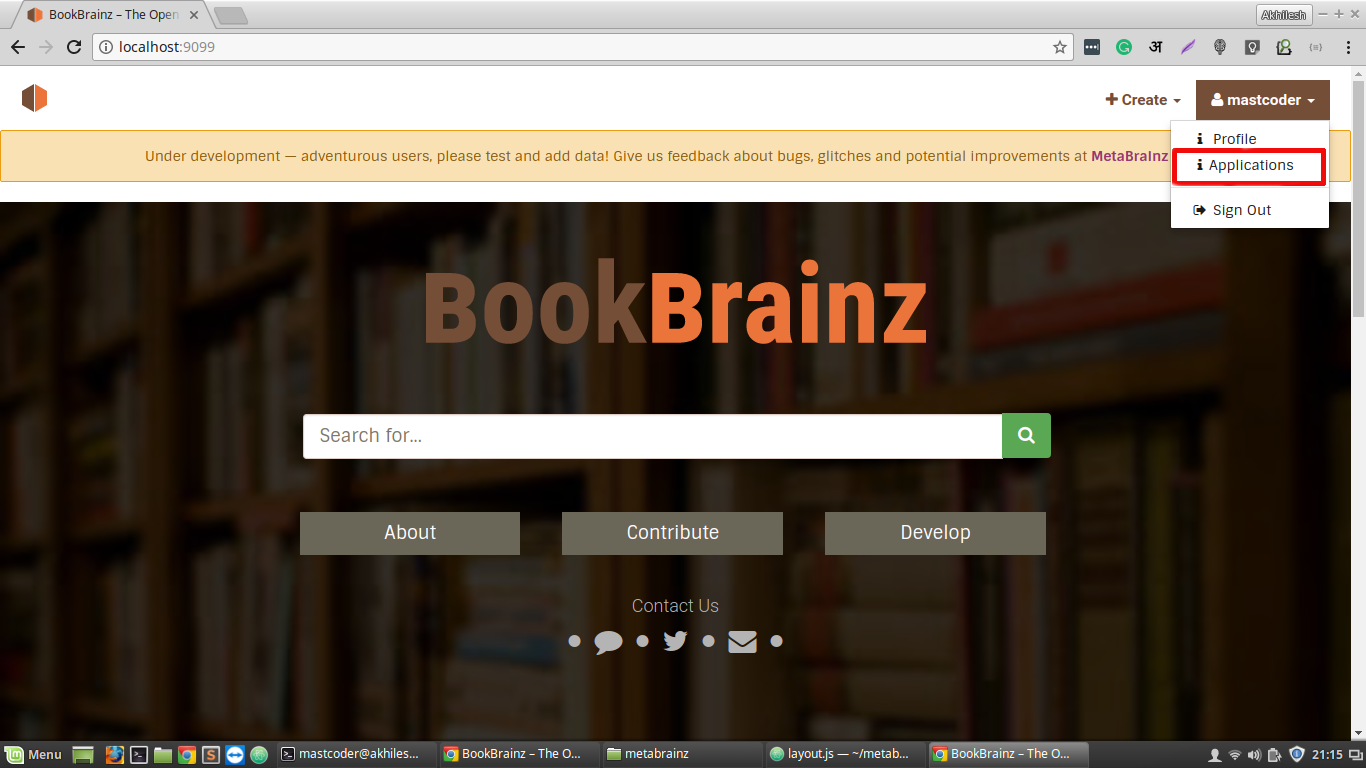
Add a page that shows client’s applications and user token

If you want to create an application, a form will be created as shown below

When an application will be created, the application page will be updated as below:

API endpoints
Here we will use REST to design endpoints. I am mentioning some endpoints below. I aim at extending these endpoints for all types of entities and also accept changes as per the requirements of the community.
GET /publication
Returns a list of publications with relevant details as JSON, ordered by the date they were added.
-
URL Parameters
Optional:
limit=[integer]: Max value: 100, default value: 100.
offset=[integer]: The offset of the first result returned from the database, by default set to 0.
orderBy=[string]: added_asc or added_desc. This will be used to sort the publications in order to created date. -
Sample Call:
Request from curl
$ curl https://api.bookbrainz.com/v1/publication/?limit=2&offset=10 \
-X GET
- Response Example:
{
"count": "1000",
"limit": 2,
"offset": 10,
"publications": [
{
"id": "08f32a73-e415-4c7e-89ed-e496a621950e",
"name": "Artificial Intelligence: A Modern Approach",
"sort-name": "Artificial Intelligence",
"language": "English",
"type": "Book",
"added": "2018-02-05 08:40:30",
"addedBy": "574",
"aliases": [
{ "name": "Artificial Intelligence: A Modern Approach", "sort-name": "Artificial Intelligence", "language": "English" },
],
"identifiers": []
},
{
"id": "8c8ca77b-2831-4a28-88d6-ca24a9b2e01f",
"name": "A Tale of Two Cities",
"sort-name": "cities, tale of 2",
"language": "English",
"type": "Book",
"added": "2017-12-05 08:40:30",
"addedBy": "739",
"aliases": [
{ "name": "A Tale of Two Cities", "sort-name": "cities, tale of 2", "language": "English" },
],
"identifiers": []
}
]
}
Get /publication/{id:bbid}
Get details of the publication with specified BBID as a JSON document.
-
URL Parameters
Optional:
relationship=[boolean]: If relationship is true, it returns the publication details with relationship. -
Sample Call:
Request from curl without relationship parameter.
$ curl https://api.bookbrainz.com/v1/publication/08f32a73-e415-4c7e-89ed-e496a621950e \
-X GET
- Response Example:
{
"id": "08f32a73-e415-4c7e-89ed-e496a621950e",
"name": "Artificial Intelligence: A Modern Approach",
"sort-name": "Artificial Intelligence",
"language": "English",
"type": "Book",
"added": "2018-02-05 08:40:30",
"addedBy": "574",
"aliases": [
{ "name": "Artificial Intelligence: A Modern Approach", "sort-name": "Artificial Intelligence", "language": "English" },
],
"identifiers": []
}
-
Sample Call:
Request from curl with relationship parameter.
$ curl https://api.bookbrainz.com/v1/publication/08f32a73-e415-4c7e-89ed-e496a621950e?ralationship=true \
-X GET
- Response Example:
Getting more details of the relationship, like edition can be accomplished by :
GET publication/{id:BBID}/edition
Returns a list of editions with their details, which belongs to specified publication.
POST /publication/create
This is used for creating a new publication. This endpoint returns the operation’s status and code as a JSON document.
-
Request Header
"Content-Type": "application/json"
"Authentication'": "<user_token>"=> It will be used to authenticate the user, each user will have a unique token that can be provided to clients for authentication. -
Request Body
{
"name": "Publication Name",
"sort-name": "Publication sort name",
"language": "Language name",
"type": "Book",
"aliases": [
{ "name": "Pulbication Name", "sort-name": "Publication sort name", "language": "Language name" },
],
"identifiers": [
{ "value" : "id", "type": "wikidata ID" }
]
}
-
Sample Call:
Here an example of a post request from the client application
var request = require('request');
// Set the headers
var headers = {
"Authentication": "5e4dd8771cf10d6d05a25945c851b4d8",
"Content-Type": "application/json"
}
var publicationDetail = {
"name": "A Tale of Two Cities",
"sort-name": "cities, tale of 2",
"language": "English",
"type": "Book",
"revision_note": "https://en.wikipedia.org/wiki/A_Tale_of_Two_Cities",
"aliases": [
{ "name": "A Tale of Two Cities", "sort-name": "cities, tale of 2", "language": "English" },
],
"identifiers": []
}
// Configure the request
var options = {
url: 'https://api.bookbrainz.com/v1/publication/create',
method: 'POST',
headers: headers,
body: publicationDetail
}
// Start the request
request(options, function (error, response, body) {
if (!error && response.statusCode == 201) {
// Print out the response body
console.log(body)
}
})
- Response Example:
{
"code": "200",
"message": "Request processed successfully"
}
PUT /publication/{id:bbid}/edit
This is used for updating a publication detail. This endpoint returns the operation’s status and code as a JSON document.
-
Request Header Parameters
"Content-Type": "application/json"
"Authentication": "<user_token>'": It will be use to authenticate the user - Request Body : Publication detail for updation
{
"id": "<BBID>",
"name": "Publication Name",
"sort-name": "Publication sort name",
"language": "Language name",
"type": "Book",
"aliases": [
{ "name": "Pulbication Name", "sort-name": "Publication sort name", "language": "Language name" },
],
"identifiers": [
{ "value" : "id", "type": "wikidata ID" }
]
}
-
Sample Call:
Here, an example of an update request
var request = require('request');
// Set the headers
var headers = {
"Authentication": "5e4dd8771cf10d6d05a25945c851b4d8",
"Content-Type": "application/json"
}
var updatedPublicationDetail = {
"id": "08f32a73-e415-4c7e-89ed-e496a621950e"
"name": "A Tale of Two Cities",
"sort-name": "cities, tale of 2, two cities",
"language": "Hindi",
"type": "Book",
"revision_note": "https://en.wikipedia.org/wiki/A_Tale_of_Two_Cities",
"aliases": [
{ "name": "A Tale of Two Cities", "sort-name": "cities, tale of 2, two cities", "language": "Hindi" },
],
"identifiers": [
{"value": "Q19675", "type": "WikidataID"}
]
}
// Configure the request
var options = {
url: 'https://api.bookbrainz.com/v1/publication/08f32a73-e415-4c7e-89ed-e496a621950e/edit',
method: 'PUT',
headers: headers,
body: updatedPublicationDetail
}
// Start the request
request(options, function (error, response, body) {
if (!error && response.statusCode == 200) {
// Print out the response body
console.log(body)
}
})
- Response Example:
{
"code": "200",
"message": "Request processed successfully"
}
DELETE /publication/{id:bbid}/delete
This is used to delete the publication with the specified BBID. When a particular publication is deleted, all editions of the publication will also be deleted.
-
Request Header
'Authentication": '<user_token>': It will be use to authenticate the user -
Sample Call:
Request from curl
$ curl https://api.bookbrainz.com/v1/publication/08f32a73-e415-4c7e-89ed-e496a621950e/delete \
-X DELETE \
-H "Authentication: 5e4dd8771cf10d6d05a25945c851b4d8"
- Response Example:
{
"code": "200",
"message": "Entity deleted successfully"
}
GET /search?{params=value}
The value of parameters will be used at the backend to generate a dslQuery. This query will be to fetch result from ElasticSearch database. The result from the query is used to fetch the entity model from orm. The model is then returned to the client in JSON format.
-
URL Parameters
Required:
q=[string]: The value of q is queryString, which we want to search.Optional:
collection=[string]: Use this to search in a specific type of entity collection like publication, edition etc.
limit=[integer]: Max limit is 100, default is 10.-
Sample Call:
Request from curl to search over all type of entity collections
$ curl "https://api.bookbrainz.com/v1/search?q=Harry Potter>&limit=1 \ -X GET- Response Example:
{ "bbid": "ba446064-90a5-447b-abe5-139be547da2e", "dataId": "1429", "revisionId": "4585", "master": "true", "annotationId": "null", "disambiguationId": "null", "defaultAliasId": "3466", "typeId": "3", "aliasSetId": "3039", "identifierSetId": "null", "relationshipSetId": "null", "type": "Work", "languageSetId": "1857", "defaultAlias": { "id": "3466", "name": "Harry Potter", "sortName": "Harry Potter", "languageId": "120", "primary": "true" } } -
Sample Call:
If we want to search on some specific collection, we pass it in the URL as below
-
Sample Call:
Request from curl to search only on publications
```
$ curl https://api.bookbrainz.com/v1/search?q=Harry Potter&collection=publication&limit=1 \
-X GET
```
- Response Example:
{
"bbid": "eaa480fa-3f95-4373-ade7-467aad674d58",
"dataId": "42",
"revisionId": "19",
"master": "true",
"annotationId": "null",
"disambiguationId": "null",
"defaultAliasId": "10",
"typeId": "1",
"aliasSetId": "44",
"identifierSetId": "null",
"relationshipSetId": "25",
"type": "Publication",
"defaultAlias":
{
"id": "10",
"name": "Harry Potter and the Half-Blood Prince",
"sortName": "Harry Potter and the Half-Blood Prince",
"languageId": "120",
"primary": "true"
}
}
GET /editor
Returns a list of editors with relevant details as JSON.
-
URL Parameters
Optional:
limit=[integer]: Max limit is 100 and by default 10.
orderBy=[string]:total_revisionORjoined -
Sample Call:
Request from curl
$ curl https://api.bookbrainz.com/v1/editor?limit=1&orderBy=total_revision \
-X GET
-
Response Example:
It will return all the editor’s information but here the example is given with only a few of the details.
{
"limit": "1",
"editors": [
{
"id": "144",
"basic_info": {
"MB_acount": "The_Catman",
"display_name": "The_Catman",
"birth_date": "1970-01-01 05:30:00",
"joined": "2015-12-10 04:39:29"
},
"stats": {
"total_revision": "384",
"revision_applied": "384"
}
}
]
}
These endpoints are not finalized and I am hoping for the discussion on these during the community bonding period to finalize the API spec before any actual coding starts.
Status Codes
These are some standard status codes for responses which we will use
200 OK – success
201 created - entity created successfully
400 Bad Request – invalid request (see source)
401 Unauthorized - Authentication failure
403 Forbidden – rate limit exceeded
404 Not Found – value not found
Authentication
The BookBrainz API will have two levels of authentication.
-
User authentication:
As shown in the above GUI upgrades, we provide a unique user token to every editor the application page.
It will be used to authenticate the user, each user will have a unique token that can be provided to clients for authentication. This type of user authentication is inspired by ListenBrainz. In the first part of the project, this will be implemented.
Sample Request:
//Example of a request to delete publication from the database
curl -i -X DELETE \
-H '{"Authentication":"5e4dd8771cf10d6d05a25945c851b4d8" \
https://api.bookbrainz.com/v1/publication/08f32a73-e415-4c7e-89ed-e496a621950e/delete
User authentication is required for such requests, which is handled by an authentication function or middleware.
This is not the exact code but isAuthenticated function looks like this:
/**
* Delete publication from the database
*
* @return {object}
*/
router.del('publications/{id}/delete', async(ctx) => {
if(isAuthenticated(ctx)){
// delete the publication from the database and send a response to the client with the status code.
}
else{
// send response to the client with authentication failure status code
}
})
/**
* @param {object} header of request
*
* @returns {bool}
*/
const isAuthenticated = (ctx) =>{
if(ctx.header.Authentication == editor.user_token) {
return true;
}
else {
return false
}
}
-
Client authentication:
-
Client authentication will be implemented in the second part of the project when we will use Kong. Client authentication will follow the key-auth type of authentication which is implemented in Kong. After the setup of the Kong server, we will generate the API key with the help of GUI for the user. This API key will be used when a client will make API requests to Kong.It will authenticate the API key and request will be forwarded to our API server if the key is genuine.
-
Kong also provides a facility for anonymous applications to access the API with some configured limitations as discussed above. We can see the configuration in detail on Kong documentation.
Rate limiting
Rate limiting will be implemented through Kong, which has many features to control the access of API by the client application. By default, Kong limits the rate of access on the basis of IP address but we can extend it to the consumer_id which is provided by Kong, consumer_id will be provided to the client when they create an application
Kong provides an API to manage the rate limiting per consumer_id or client application. We have many more options to set rate limiting here.
Caching
Caching will be managed by using Redis. It uses lazy loading concept for caching. As shown in the example when the server gets a GET request from the client, first check if the required result is present in the cache, if yes, then it will return that to the client. Otherwise, a query will be sent to the database or the ElasticSearch and this response will be updated in the cache then the server responds to the client.
Here the example of basic cache implementation.
const Router = require('koa-router');
const router = new Router();
var redis = require('redis');
var cache = redis.createClient(6379, '127.0.0.1');
/**
* to search over all type of entities
*
* @return {object}
*/
router.get('/search', async(ctx) => {
var query = ctx.request.query.q;
cache.get(query, (error,queryResult) => {
if(error){throw error}
if(queryResult){
ctx.response.json(JSON.parse(queryResult));
}
else{
queryResult = await queries.search(query);
// store the key-value pair (query:queryResult) in our cache
// with an expiry of 1 hour (3600s)
cache.setex(query,3600, queryResult);
// return the result to the user
ctx.response.json(JSON.parse(queryResult));
}
})
})
To manage the cache in one Redis server, it will need to implement namespacing as a cache module. Cache module will be imported, when it is required. This will follow the ideas explored in brainzutils and adapt it for our purposes.
-
Cache invalidation
The TTL(time to live) in the cache of a key will depend upon the frequency of change of the data in the database.First, we analyze that which type of data is changing frequently and which data is changing slowly. Data which changes less often will have larger TTL while those which are expected to change frequently will have a short TTL. When an edit request(POST, PUT, DELETE) will come from BookBrainz site or API, update the database according to request and delete the related cache data from Redis database.
Documentation
At the time of coding, we will use JSDoc to document the code. After all, endpoints have been implemented we can document the final API at BookBrainz User Guid.
Proposed Timeline
A broad timeline of the work to be done is as follows:
Community Bonding (April 23 - May 14):
Spend this time learning koa.js, use of Kong and trying to formalize what exactly I need to code and
discuss design decisions with the mentor to make sure that no bad decisions are made early in the process.
Get clarity about all endpoints of the web service.An exact specification of what endpoints needs to be added will be delivered upon the completion.
Here is a more detailed week-by-week timeline of the 13 weeks GSoC coding period (14 May - 6 August) to keep me on track:
-
Week 1 (May 14 - May 20): Begin with upgrading schema, add application page with the user token.
-
Week 2 (May 21 - May 27): Complete GUI upgrades with
create-applicationfunctionality to create an application and generate API-key. -
Week 3 (May 28 - June 3): Setup the basic project structure and start implementation of endpoints
GET /publication/{id: BBID},GET/editor, andGET /creatorwith tests. -
Week 4 (June 4 - June 10): Implement the cache module, ensure that above endpoints work properly using cache module.
-
First evaluations here
-
Week 5 (June 11 - June 18): Implementing all the endpoints related to publications with tests.
-
Week 6 (June 18 - June 24): Implementing all the endpoints related to editions with tests.
-
Week 7 (June 25 - July 1): Implementing all the endpoints related to the work and creator with tests.
-
Week 8 (July 2 - July 8): Implementing all the endpoints related to the publisher with tests. Check the working of all endpoints related to all entity-types. Also, check the relationship between entity-types and data-update requests like - POST and PUT.
-
Second evaluations here
-
Week 9 (July 9 - July 15): Implementing all the endpoints related to the search query and editor with tests.
-
Week 10-11 (July 16 - July 29): Setup the Kong server as middleware to implement key-auth and rate-limiting, then with the help of Kong admin API enables the key-auth for the BookBrainz API, provide access to the anonymous clients. Enable the rate limit feature for both authenticated as well anonymous clients.
-
Week 12 (July 30 - August 6): Documenting the BookBrainz API service for the developers with examples.
-
Week 13 (August 7 - August 14): Work on final submission and make sure that everything is okay.
-
After Summer of Code
Continue working on BookBrainz. Resolving issues on this project reported by API users.
Move the focus to collect Books data from the open data libraries and other available sources.
Detailed Information About Me
I am a senior undergraduate computer science student at the National Institute of Technology, Hamirpur. I came across BookBrainz when one of my friends told me that MetaBrainz organization has a project in BookBrainz using Node.js platform as the backend and React as frontend and ElasticSearch for searching. I was interested in these technologies and had prior experience working on them too so I started reading the code base slowly from Nov 2017 and contributing. Here is a list of my pull requests. I am currently working on this project to add a statistics page to take overviews of BookBrainz activity. I have learned many new things from the MetaBrainz community. 
Question: Tell us about the computer(s) you have available for working on your SoC project!
Answer: I have a DELL laptop with an Intel i5 processor and 8 GB RAM, running Linux Mint 18.1 Serena.
Question: When did you first start programming?
Answer: I started programming in high school writing small C++ programs. Started programming in web design technologies as a freshman in college.
Question: What type of books do you read?
Mostly non-fiction biographies like Biography of Mahatma Gandhi, Narendra Modi : A Political Biography and Jyotipunj . I have also read some fiction from Chetan Bhagat like - Five Point Someone and One night at the Call Center.
Question: What aspects of the project you’re applying for (e.g., MusicBrainz, BookBrainz, etc.) interest you the most?
Answer: BookBrainz interests me since I really like the idea of keeping data open and free for public use. The project can be developed so as to have a publically accessible dump of literature data, which will expand over time with more editors and the data dump can also be used to create efficient book recommendation engines to serve a large community of worldwide readers.
Question: Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
Answer: I have worked on a bunch of personal projects that I have open-sourced like temples of india, CSMS and Agricultural App.
Question: What sorts of programming projects have you worked on?
Answer: During last summer(2017), I interned at IIT Bombay and worked on a project for creating a database of Temples of India, my work involved creating a site to interface with the data - search for the temple, edit temple information, comment and rate on temple’s page. I wrote frontend and backend from scratch, UI using ReactJS and backend in Node.js using Express framework. I wrote the search functionality by querying ElasticSearch database. I also worked on a Co-operative Society Management System, a desktop application to manage accounts, loans, and transactions in a co-operative bank. The project was written in Python, creating GUI using Qt5 and MySQL for the database which was interfaced by SQLAlchemy. When I was learning Java, I created a basic shop inventory system for learning the fundamentals.
Question: How much time do you have available, and how would you plan to use it?
Answer: During 1-14 May, I will be busy because of my semester exams, but I will still try to participate in IRC.
I am absolutely free after 15th May and can work full time (45-50 hrs per week) on the project until the final submission.
Question: Do you plan to have a job or study during the summer in conjunction with Summer of Code?
Answer: None, if selected for GSoC.
