Personal information
Nickname: Leo Verto
IRC nick: Leo_Verto
Email: leotheverto@gmail.com
GitHub: LeoVerto
Proposal

Overview
In recent years MusicBrainz has had major problems with spammers abusing it to direct search engines to their websites. During the 2017 summit in Barcelona we discussed possible mitigation techniques and @yvanzo has already started work on the spam ninja system to allow community moderators to handle reported spam.
SpamBrainz is intended to plug into the existing report system, scan all new account creations and edits and automatically report them if it considers them to be spam. The spam ninjas will then either accept or decline the report and feedback is sent back to SpamBrainz to improve the detection process.
In the future once SpamBrainz reaches a high enough accuracy, it could also be used to automatically remove spam. It should also be somewhat easily extendable to handle other MeB projects.
Technical Overview
SpamBrainz will be a seperate, Python-based service with direct read-only access to the live MusicBrainz database and an authenticated REST API for the edit and user IDs to be scanned to be submitted to. This will run on a Flask web server.
On the MusicBrainz side of things a MB cron job is run every 10-30 minutes which submits all the entries created since the last run to SpamBrainz’ API.
SpamBrainz will then calculate the spam scores (more on that below) and create reports either as ModBot or a seperate SpamBrainz user. Whether these reports will be directly written to the DB à la ModBot or a new MB API endpoint has to be created has still to be decided.
Upon a ninja’s action, the Spam Ninja system will then send a binary feedback to the SB API to further train the system.
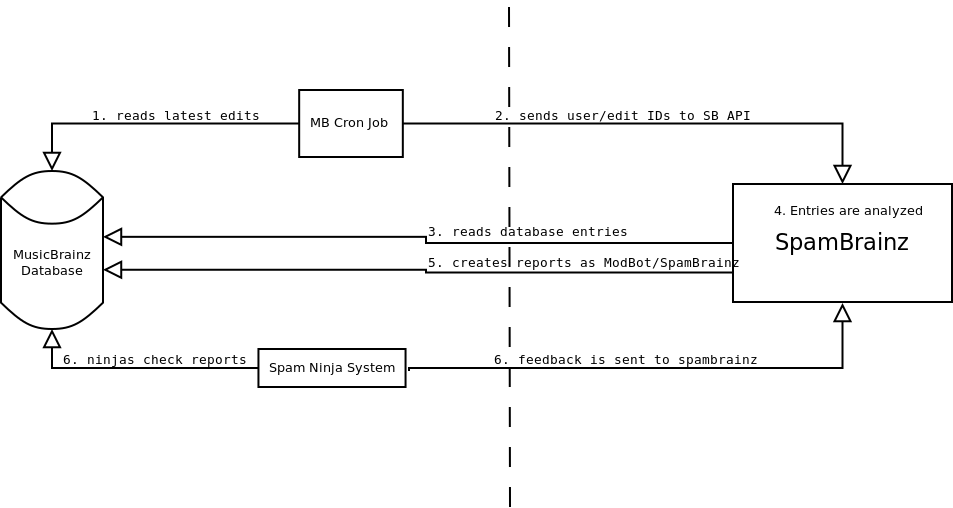
SpamBrainz Overview (sorry for butchering both flow charts and UML).
SpamBrainz Internals
With SpamBrainz being a completely new project a significant part of this project will be designing the service and the API. Most importantly though I will have to figure out what methods work best for detecting the kind of spam MusicBrainz is dealing with, especially considering we don’t have text-only spam but linked entities which makes the process more difficult but can also provide data.
SpamBrainz should be designed in a modular fashion to allow testing different detection systems and even chaining them to improve accuracy. The initial system is going to be a handcrafted heuristic system that will rely on additional data points like the user’s edit history, their email provider, whether they’ve interacted with the community before and running submitted URLs against a list of known spam domains.
In order to make the system trainable, a module based on machine learning is required. To do this, I will build and train a neural network using Keras with a TensorFlow backend.
The network will first be trained offline on batches from a dump of collected spam data and known good data (a somewhat random selection of legitimate editors, including newer ones) allowing me to tweak the network layout and hyperparameters (optimizer, learning rate, etc.). Once I’m happy with the network’s performance it will be moved to the SpamBrainz production server and further trained online or incrementally using spam ninja feedback as the classifier.
The potential problem with this is that while this should reduce the Type 1 error (i.e. false positives), additional training with known good data might be required to also reduce the Type 2 error (false negatives). This could be implemented by either automatically submitting known good data from certain editors or manually having the spam ninjas do it.
The deleted spam data doesn’t inherently require a seperate database. Using hidden tables, it can stay part of the MB database but not be part of the regular data dumps, although a seperate dumping script to generate a usable dataset for offline learning should be considered in this case (user emails have to be removed from that dump).
The final result of the whole detection process will be a score from 0-100 indicating SpamBrainz’ certainty that this is in fact a spam edit/user. The threshold for which reports are created should also be easily changable, possibly as part of the spam ninja interface.
SpamBrainz also needs to have extensive monitoring (with integration into the existing Grafana) to see the long-term performance differences and to allow fast reactions to new spam techniques.
Timeline
Seeing as I’ve never built anything on this scale from the ground up, I had some trouble coming up with a concrete timeline but I tried to come up with estimates for the tasks involved in the project.
- Week 1: Take a look at the existing spam in MusicBrainz, investigate existing FOSS spam detection systems that could be relevant to SpamBrainz.
- Week 2: Design SpamBrainz’ API and project structure.
- Weeks 3-5: Build the API and the SpamBrainz backend which the detection modules can plug into.
- Week 6-7: Build a heuristic system to get a good idea of which data points are good indicators for spam and which aren’t as well as to get a good baseline spam score.
- Weeks 8-11: Create the machine learning module and tweak the hyperparameters to hopefully get it to a usable state.
- Week 12: Documentation, designing a simple website explaining SpamBrainz to our end users.
- Week 13: Buffer period.
Detailed information about yourself
- Tell us about the computers you have available for working on your SoC project!
Desktop and Laptop running Linux with decent hardware and recent NVIDIA GPUs for machine learning. - When did you first start programming?
Probably around age 10 or 11, using AntMe! to learn cough Visual Basic. - What type of music do you listen to? (Please list a series of MBIDs as examples.)
Mostly EDM, synthwave/synthpop and also some regular pop.
Examples: The Glitch Mob, Giorgio Moroder, Lorde. Check out my ListenBrainz page for more artists I like.
Spotify.me tells me I listen to a lot of indietronica although I’ve never heard of that genre before. - What aspects of the project you’re applying for interest you the most?
The idea of getting to apply the machine learning knowledge I’ve taught myself in a real-world situation where it can actually do something good. - Have you ever used MusicBrainz to tag your files?
Obviously, that’s how I found out about it. - Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
Nothing major outside of MeB projects, inside MeB mostly BrainzBot and some BookBrainz stuff ages ago. - What sorts of programming projects have you done on your own time?
Tons of different stuff, recently I’ve been working on a project to teach an artificial neural network to convert colours from RGB to LAB where I discovered the mess that is scikit-image. - How much time do you have available, and how would you plan to use it?
I can probably work full time on the project although I’ll still have to study and write exams towards the end of the GSoC time. - Do you plan to have a job or study during the summer in conjunction with Summer of Code?
I’m going to study during the summer until July 20th after which I’ll have exams.
For the last couple years I’ve volunteered for a local summer camp project working with teenagers, if possible I’d like to do that again this year. This takes place from July 9th to July 19th and although I could take my laptop with me, I can’t guarantee a reliable internet connection and I definitely wouldn’t be able to work full time on GSoC.

