Personal Information:
- Name: Suyash Garg
- IRC Nick: ferbncode
- Email: suyashgargsfam@gmail.com
- Github: https://github.com/ferbncode
- LinkedIn: https://linkedin.com/in/gargsuyash
Project Overview:
Presently, CritiqueBrainz uses python-musicbrainzngs to show search results and fetch info of selected entities. python-musicbrainzngs then uses the XML Web Service which returns the requested results. This is not very slow but some pages on CritiqueBrainz require a lot of MusicBrainz data, which takes very long time to retrieve. For example, as suggested in CB-162, if the cache is empty and each user requests separate pages of the review browsing section, then there are 330 X 27 requests to the web service. Directly accessing the MusicBrainz database would mean one query(directly to the database) per page(by getting multiple entities’ data in a batch using raw SQL statements) only if the cache is completely empty. Thus, directly accessing the MB database would result in significant increase in speed with which CB loads.
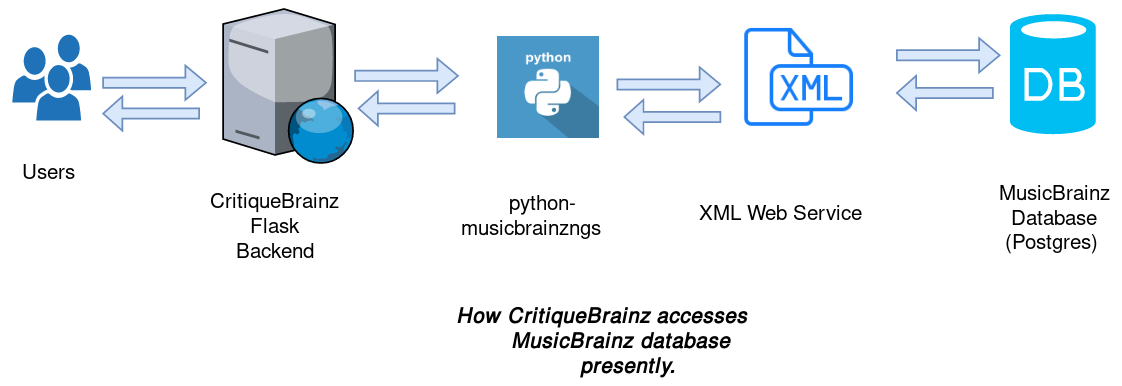
Migrating off python-musicbrainzngs and directly accessing MB Database:
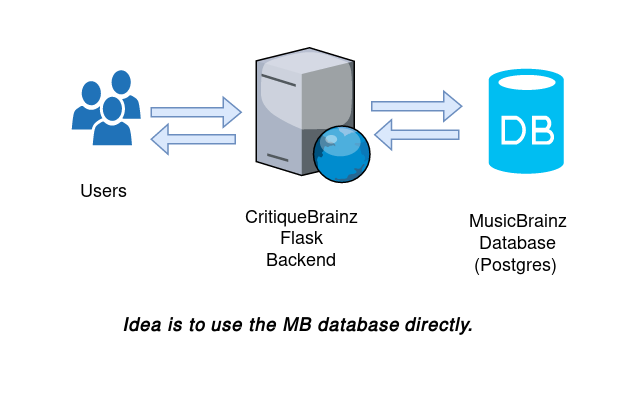
What I propose to do can be described in the following subtasks:
-
Setting up the development environment for accessing MB Database: MB database would be made available in the development environment by setting up a separate docker container. This can easily be achieved by using the musicbrainz-test-database docker image and then importing the MusicBrainz data dumps. Using this docker image ensures that future schema changes in MusicBrainz database don’t break the build environment for CB development. Accessing the MB Database would be made an option in config files as some users might not be willing to download the database dumps.
-
Directly use the MusicBrainz Database: CritiqueBrainz presently allows reviewing release groups, places, and events. Directly accessing the MB database would require writing SQL statements for accessing the info regarding different entities.
-
Improving User Experience: Issues like CB-80, CB-84, CB-93, CB-140 can be resolved by using the MB Database directly. Consider release groups, data fetched via the WS was difficult to separately sort by release year. Using MB database directly would facilitate doing such things and improving the user experience. Other music review sites like rateyourmusic have artists albums sorted by release dates (see example). CritiqueBrainz presently does not do so (see example). I will also work on issues CB-36 and CB-198 for enhancing ways in which reviews are shown.
Implementation Details:
Setup:
Using the MB Database would be made a configurable option for development. This can be implemented using separate docker-compose files for the build. For adding the MusicBrainz database docker container, this existing docker image would be used.
The MusicBrainz database will reside in a separate docker container in the development environment. I would then update the CritiqueBrainz build documentation.
The existing docker-compose files would then include making another docker container using the musicbrainz-test-database image. Dumps can be then downloaded and extracted. The database can be then populated using the COPY command that PostgreSQL provides. There are two options for achieving this: a bash script to run in the container or adding function in manage.py for adding data dumps to the MB database. Any of the two options can be used. I have started some work on the MB database access part. I would also write functions for validating dumps using md5sums, checking for correct SCHEMA SEQUENCE and TIMESTAMP and checking for disk space on the host device.
Writing Database Queries:
For getting entity info, we could get most information using joins on many tables(for example, considering release groups, information like artists, artist_ids, primary_type of a release_group, release_group_name, release_group_id can be attained at once using tables artist_credit, artist, artist_credit_name, release group and release_group_primary_type). For information like related URLs and tags of entities, we may need to make separate queries. An example function for querying release group info from release group id is shown below. An important point is that release group information needed on the browse-reviews can be easily batched using SQL operators like IN etc. The retrieved data will be cached as it is presently done.
The frontend/external/musicbrainz/ will contain the following files.
-
init.py: This file will contain functions like
init_mb_db_engineto use SQLAlchemy for querying mb_database.(see example), This file will also contain wrapper functions to decide which functions to call (direct database access or web service based functions) based on the set config. Other modules can then access these functions to fetch the data. - search.py: This file will contain the existing search functions which query the WS to get search results.
These files will contain the existing functions which access the WS as well as MB Database access functions:
-
artist.py: This file will contain the following functions:
- get_artist_by_id: Get information related to an artist like name, artist area, external links etc.
- get_artist_urls: Get external links of an artist. Also arranges external links of artists into dictionaries with keys like AllMusic, WikiData, etc.
- get_artist_relations: Get artist relations like members of a band or band of an individual artist. Arranges relations properly into dictionaries.
-
event.py: This file will contain the following functions:
- get_event_by_id: Get information related to an event like event name, artists performed, place etc.
- get_artist_rels: Get artists that have performed at an event. Also arranges artists into dictionaries with keys like Main Performers, Supporting Acts, etc.
- get_place_rels: Get place info of where the event was held.
-
place.py: Functions like:
- get_place_by_id: Get information related to a place like location, coordinates, type of the place.
-
get_artist_rels: Get information related artists performed at those places.
and other similar functions.
-
release_group.py: For fetching information related to relase_groups and releases:
- get_multiple_release_groups_by_ids: Get information regarding a bunch of release groups. The information returned would include the artist MBID, artist name, release group MBID, release group type and release group name.
- get_release_group_rels: Get external links of a release group. Also arrange links in dictionaries.
- browse_release_groups: browse release groups of an artist. The data here would also contain primary types and then would be arranged into a dictionary.
- browse_all_releases: Get all the releases of a certain artist or a release group.
- get_release_by_id: Get info about a release like recordings, recordings length etc.
- get_release_group_by_id: Get all info about release_group. This includes getting external links, tags etc.
- db_helpers.py: This file will have helper functions similar to Search Server. These functions can be used to fetch information which is common between entities. (eg. tags)
- tests/: This directory will contain files artist_test.py, event_test.py, release_group_test.py, place_test.py for testing functions in above files.
Fetching information of entities and Improving User experience:
After setting up the docker containers and getting things started, I would help setting up access of MB Database on the production server. Any of the running instances of MB Server can be connected to CB. A Mirror server will be the best to connect CB to.
I will write functions to access entity information from the MusicBrainz Database. An example function to fetch information regarding a release_group can be found here. l_*_* tables are used in MB Database to link corresponding rows in entity tables. Also, in MB database, links suggest the kind of relation between the entities. For eg, there are artists which can be the guest or main performers at an event.
I also plan to have a bunch of helper functions that would help to get related information of entities. For example, multiple entities can have tags. Thus, a helper function would be good to have which would accept the entity and relation table name and return tags related to the entity. See example below.
After using raw SQL to access entity info, small tweaks in DB access functions like order by timestamp (For eg. ordering release groups of an artist by release year using table release_group_meta) can be done to solve issues like CB-80. Similar tweaks can be done to show releases with bonus tracks. I plan to solve these and some other issues alongside while writing database access functions to improve the user experience. Tests will be written for all functions also.
Timeline
A broad timeline of my work during summer can be summarized as below:
-
Community Bonding (May 5 - May 29): Will start setting/completing up the docker containers for the development environment of CB. Also, discuss design decisions with the mentor.
-
Phase I (May 30 - June 20): Complete setting up MB Database for development environment using docker containers. Adding a function to
manage.pyor writing a script for importing mbdumps will also be part of this task. Also, update the CritiqueBrainz build documentation. Also, help setting up changes in the production server. In this phase, I also aim to complete database access functions forplaces. -
Phase II (June 21 - July 20): I plan to complete database access functions for
release_groupandartists. Also, I will modify entity info functions to improve user experience and thus close the associated issues. -
Phase III (July 21 - August 29): I will complete all database access functions in this phase. I will work on improving user experience and issues for displaying entities only with reviews. Also, spend time fixing bugs.
-
After GSoC: Continue working on CritiqueBrainz and maybe other MusicBrainz Projects. Implementing the rating system in CritiqueBrainz would also be an interesting work to do.
A detailed timeline of my work is as follows:
- Week 1: Begin with the docker setup of MusicBrainz database for CritiqueBrainz development environment. Make building MB database docker a separate option by using a seperate docker-compose file. Also, alter config files for the option to use the MusicBrainz database. Start with functions to check the md5sums of dumps, SCHEMA SEQUENCE checks` and other tasks.
- Week 2: Complete with the docker setups. Update build documentation for CritiqueBrainz. Complete functions or script for importing mb_dumps to the docker container.
- Week 3: Help setting up changes in the production server. Also, begin with DB access functions for places.
- Week 4: Complete DB access functions for places. Also, begin with the DB access functions for artists.
- Week 5: Complete DB access functions for artists. Write tests simultaneously.
- Week 6: Write functions for accessing information regarding release groups.
- Week 7: Complete writing functions for release and release group information. Keep tweaking functions for improving results displayed.
- Week 8: Complete any pending stuff. If not, start with functions for events information. Complete functions for fetching event info (and tests simultaneously). Improving UX stuff by ordering releases and release group information according to desired sort(release dates, for instance).
- Week 9: Complete previous week’s tasks and start working on filters to show review only entities.
- Week 10: Complete any pending stuff.
- Week 11: Work more on user experience issues.
- Week 12: Complete previous week’s tasks. Solve bugs.
- Week 13: Complete any pending stuff. Work on final submission.
About me:
I am a Computer Science student at National Institute of Technology, Hamirpur. Here is a link to my contributions to CritiqueBrainz.
Tell us about the computer(s) you have available for working on your SoC project!
I presently have a Lenovo laptop with 2 GB RAM and Intel Pentium P6200 processor running Arch Linux. Also, I use vim for all my development.
When did you first start programming?
I started programming in high school writing small C++ programs. Started programming in Python as a freshman in college.
What type of music do you listen to? (Please list a series of MBIDs as examples.)
I listen mostly to rock, switching to metal and pop occasionally. I love listening to songs by Linkin Park, Foo Fighters, Radiohead, Muse, Coldplay, Metallica, Guns N Roses and Thiry Seconds to Mars. My top listens presently are Sultans of Swing and Everlong.
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
I love music and love to read reviews of other people about the music I hear and the music that interests me. Reviews submitted to CritiqueBrainz can be used for various purposes such as ranking albums, sentimental analysis etc. This is why I am interested in CB.
Have you ever used MusicBrainz to tag your files?
Yes, I’ve been using Picard to tag my music collection for a few years.
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
I have contributed to GNOME Music and learnpython.org. Three patches to GNOME can be found here, here and here and contributions to LearnPython.org can be found here. I have also made a small contribution to MusicBrainz server and a small build fix in ListenBrainz.
What sorts of programming projects have you done on your own time?
I have made a working auto drive car using the Raspberry Pi (https://github.com/ferbncode/AutoDrive), also made a website in flask called Sentikart for sentimental analysis of user reviews on e-commerce sites. I have also worked on a simple music genre classifier GenreM using Logistic Regression. My other projects include a self-playing hex game bot which uses minimax to decide moves.
How much time do you have available, and how would you plan to use it?
I have holidays during most of the coding period of GSoC and would be able to give 40-50 hrs per week to my project.
Do you plan to have a job or study during the summer in conjunction with Summer of Code?
Not if I get selected for GSoC.
