A friend asked me to give 5 bands that show what I’m into. Initially I was going to give him my top 5 by playcount. But that is potentially less interesting. Imagine a user who listens mostly to 10 artists, 6 of them rock groups. The top 5 could be polluted with rock groups, while hiding indie or jazz groups the user also likes.
If we can algorithmically define a band’s similarity to other bands, then choose a representative band from that group, we could compile 5 bands that cover as much of the projected space as possible. (That’s a somewhat large “if”.)
For example:
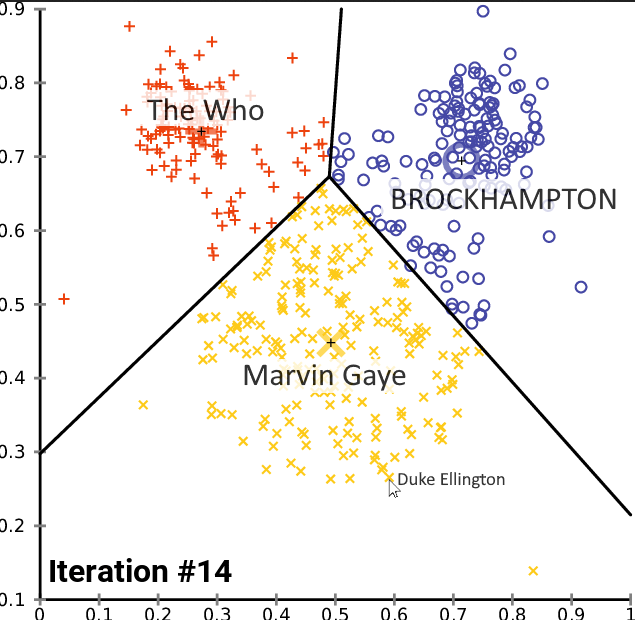
Map every band a user listens to into N-dimensional space. (Say, 2-dimensional for easier visualization). Could use multidimensional scaling (MDS) or any unsupervised method.
Split the bands into K clusters, maximizing the distance between the clusters (typical of clustering algorithm). A representative median (i.e., an actual band and not a combination of several bands) should be chosen, so K-medians could be used for example. (Further reading and page 2). If K=5, we choose 5 bands to represent a user’s taste.
I don’t know how this would handle a user who only has J<K major interests/genres. If I listen to 90% jazz I might not want my “representative” clustering to pick 1 jazz artist and some other bands I barely heard (pop, country, rap, ambient).
If some 2-dimensional projection is used, this could potentially lead to an interactive graph. Each point would be a band, and the user could explore similar artists. Quick mockup: