You are correct. The Picard aspect is a bit odd as I began early mentioning there is no metatag for performance, thus no script variables even with database entries for ‘recorded at’. And there will two of them. One group for release, and one for each recording.
An effort on the server side to normalize columns to show recording locations when a live attribute exists for searches. That should be most of it.
Thanks for the RE ideas. I’m trying recursive ones ATM, but my Fu is not that good
Its not odd at all - Musicbrainz has a massive number of relations and returning relations as standard is VERY VERY expensive in CPU.
But it is almost certain that the performance relationships are available through the API, which means that Picard can access them if you write a Plugin to make the additional API calls.
This page shows how entities are connected to each other by relationships.
So you start with a recording MBID and from that you can get Events, and some Events are Performances or Recording events and from that you can get places and dates.
But the MB data will have to be consistent for such a plugin to work consistently on your music files.
P.S. Please feel free to plagiarise any of my plugins as a starting point for your own.
One thing you will want to look at is whether the same MB event data is used for the various recordings made at the same concert - because I suspect that they may be different Events internally (i.e. different Event MBIDs) even if they hold the same data. But if they are the same MBIDs then you should try to decode what my Artists Official Website plugin does - because it does some clever stuff to avoid duplicate parallel queries and to cache the responses so that later queries are also avoided.
P.P.S. If you start doing a query per track/recording to see what events there are, the number of requests you make to the MB server will increase from 1 or 2 per album to 1 or 2 per track - that is an order of magnitude or more calls to MB - so expect your albums to take a LOT longer to load in Picard.
I have some experience already processing JSON using the ws/2 API. I think my best first effort should just be to provide the ‘recorded at’ stuff as script variables for tagging and file naming scripts.
And maybe a clean procedure for stripping disambig of duplicated info
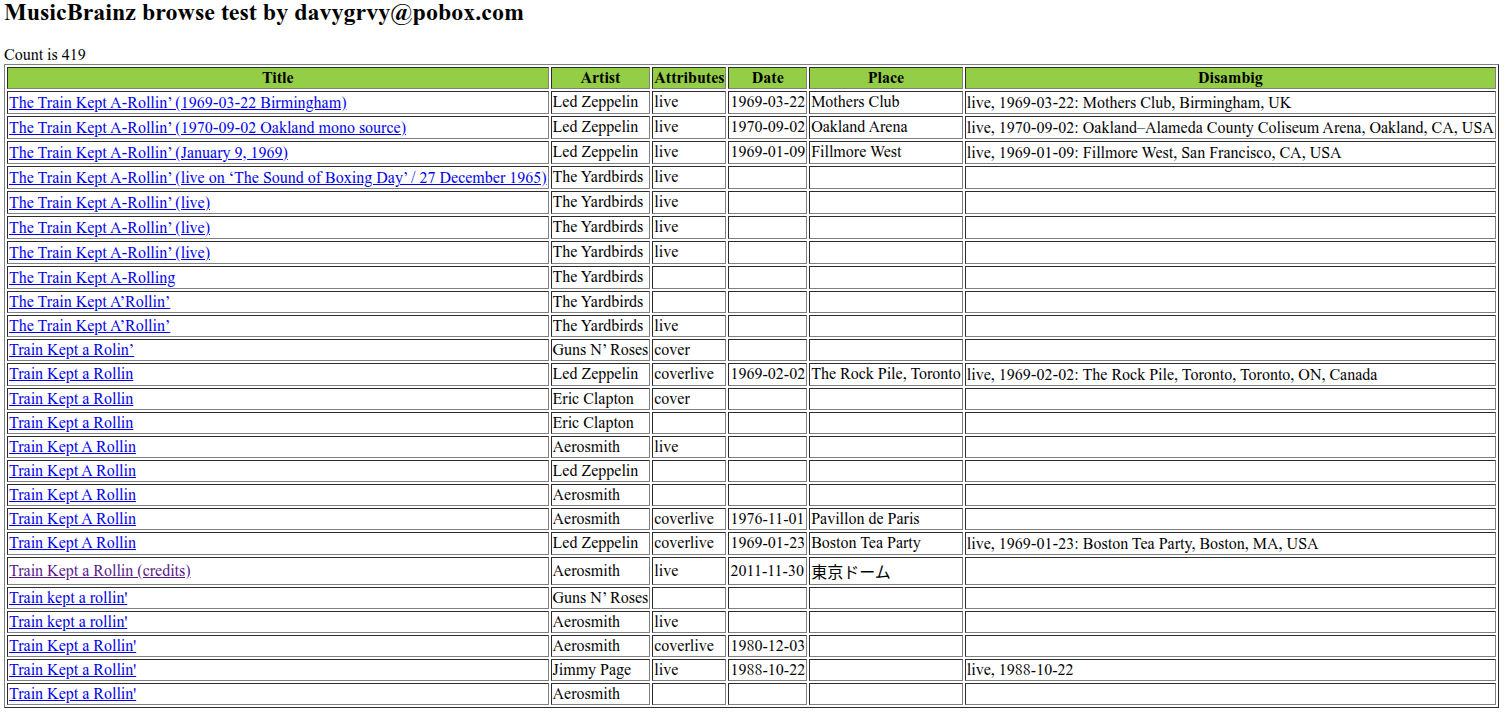
@IvanDobsky has laid out the reasons why I would be against this change. These disambiguations can be very helpful, if not a necessity, when browsing and editing.
On the other hand, automating this kind of disambiguation/display would be useful (similar ticket here) - but that needs to happen before any data is changed.
Trying to differentiate between a bunch of recordings of the same name with a disambiguation of just ‘1st show’ sounds like hell tbh
In one direction - if an author makes their source available as open source, then you should indeed feel free to use the implied offer of allowing you to plagiarise it. And I am passionate about open source, both as a user and a contributor - and my offer above was a reinforcement of a prior implied offer and not something new.
But equally, FOSS does not cover copying code which has not been offered as open source by the original author.
Then take control of how you view the database. I was messing around at the commandline last night and put that XSL transform in a file called browse.xsl
offset= sets the start position. I’m having fun checking that live recordings have relationships for venue. the work= is for a MBID. Many possibilities exist beyond browsing, but that transform is only set for decoding a list of recordings. I might make this into a bash script for my personal needs. Run your own MusicBrainz website to control the view you want
0BSD is often not the way to go as far as I am concerned. I am not happy that e.g. Amazon makes a shedload of money as a direct consequence of using open source but doesn’t pass some of that on to the people who wrote that open source to cover ongoing development and support.
So personally I am happy for my own open source projects to be used by individuals and corporations just so long as they are not sold as a product/service or as part of a product/service. If people want to make money directly off my efforts then they need to use an alternative license that directs part of their revenue to support the ongoing development and support.
0BSD won’t stop an individual’s whims collapsing the world. left-pad was already open source, and on git-hub but that didn’t stop the chaos. And 0BSD is about what licensees are legally allowed to do and NOT about copyright ownership of code.
But what would have been worse in the left-pad case would have been handing ownership of an open source package over to a corporate who might delete it, or inject malware - or indeed for the original developer on a different whim to inject malware. And a 0BSD license doesn’t stop any of that.
I mean, imagine the chaos if Linus Torvalds introduced malware into the Linux kernel?
But leaving aside all of the above, widely used packages need to survive the death of the original developer - and when they die then what happens? Longevity needs a plan to survive deaths of developers.
The only real solution is:
Create classifications of open source based on ecosystem importance (number of users).
Somehow ensure that vital packages have appropriate checks and balances to ensure longevity and avoid chaos.