Clean up the Music Listening Histories Dataset
Note: Kindly refer to this Google-Doc for a better-formatted & up-to-date document!
Name: Prathamesh S. Ghatole
Email: prathamesh.s.ghatole@gmail.com
Linkedin: https://www.linkedin.com/in/prathamesh-ghatole
GitHub: https://github.com/Prathamesh-Ghatole/
IRC Nick: PrathameshG[m] (@prathamesh_ghatole:matrix.org)
Mentor: alastairp
Timezone: Indian Standard Time (GMT +5:30)
Languages: English, Hindi, Marathi, Japanese
Abstract:
The Music Listening History Dataset is pretty damn impressive;
It contains ~27 billion logs of real-world data from last.fm scrobbles distributed into 18 chunks summing up to ~611.39 GB of compressed text files. This results in 583k users, 555k unique artists, 900k albums, and 7M tracks.
Here each scrobble is represented in the following format:
timestamp, artist-MBID, release-MBID, recording-MBID.
Unfortunately, this data has some significant fallbacks due to last.fm’s out-of-date matching algorithms with the MusicBrainz DB, resulting in frequent mismatches & errors in the release-MBID data, affecting the quality of the available dataset.
Source: https://simssa.ca/assets/files/gabriel-MLHD-ismir2017.pdf
Overall, the goal of this project is to create an updated version of the MLHD in the same format as the original, but with incorrect data resolved and invalid data removed.
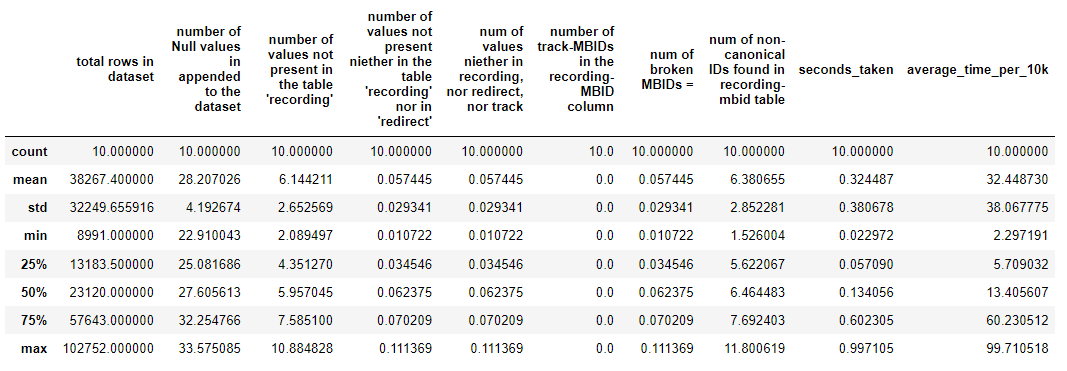
So far, our tests reveal ~6% of the recording-MBIDs are problematic, 0.05% of the recording-MBIDs have unknown issues, However, there may be more underlying issues with the dataset, such as the artist conflation issue. (Scroll down)
Given the sheer size of this project, the primary aim for this project within the relevant timespan of GSoC would be to evaluate the data and to build an efficient & scalable algorithm in Python & PostgreSQL to scrutinize and fix input data within a sensible timeframe.
MLHD Folder Structure
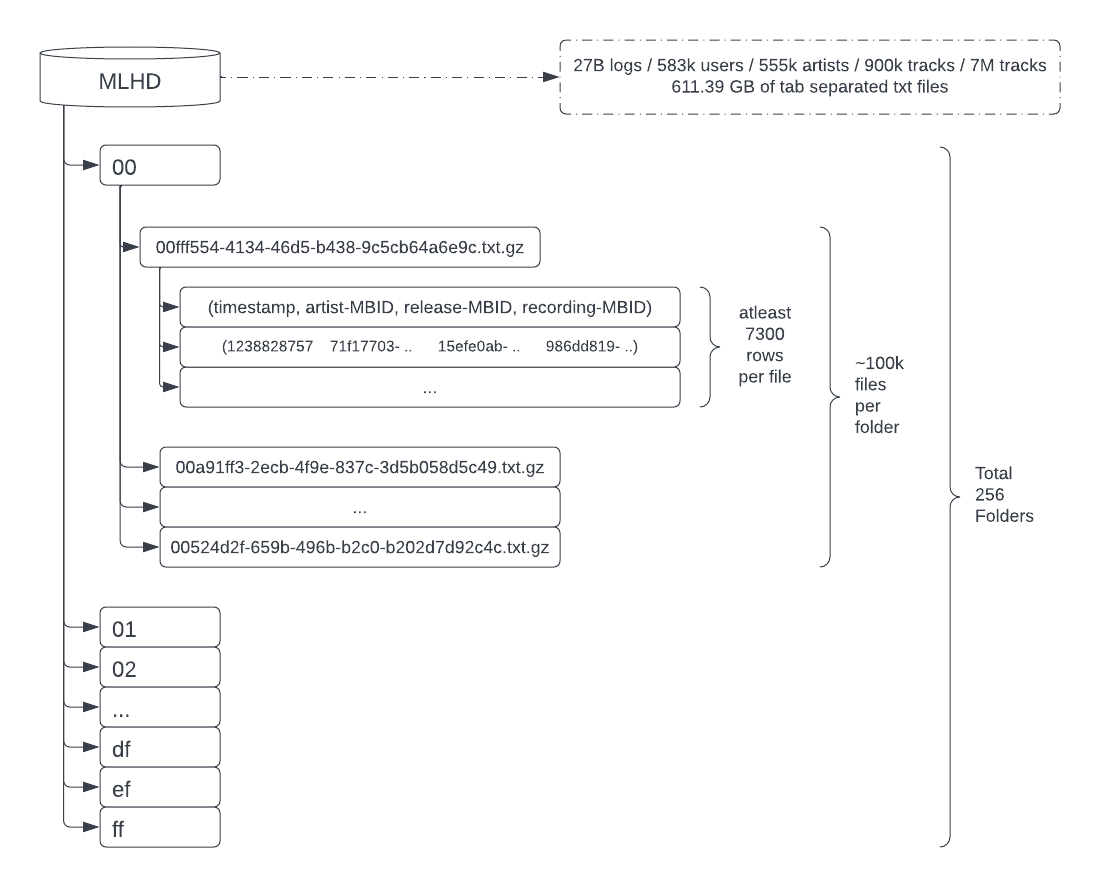
Some of these issues are as follows:
-
Conflated artists:
-
Many artists have common names.
e.g. We have 18 Daniels in the MusicBrainz database alone! -
We’re unsure if the artist column in the MLHD is correct in cases where there are many artists with the same name.
-
i.e. If a performance by an artist with a similar name ends up on another artist’s page with the same name as the first.
-
Here, we’d like to verify if the performing artist specified in the recording-MBID page matches the artist specified in the artist-MBID column.
-
Currently, there are no statistics available for how often this issue occurs.
-
-
Non-canonical recording-MBIDs:
-
Many recordings are released in many different albums.
If you were asked to pick one consistently, which one would you pick? That question is answered by canonical recordings. -
We want to replace all non-canonical recording MBIDs to one consistent canonical-recording MBID.
-
Our tests reveal ~ 6% of the verified MBIDs are non-canonical.
-
-
Alternative (Redirectable) recording-MBIDs:
-
Some recording-MBIDs could be “retired” or replaced with a newer MBID.
-
In such cases, it should be replaced with the most updated recording-MBID.
-
-
track-MBIDs being mistaken for recording-MBIDs:
- The hypothesis says some track-MBIDs have been put in the recording-MBIDs columns.
- We’d like to test this, and resolve the track-MBIDs to their recording MBIDs.
- So far, these issues haven’t been observed in our tests.
-
Invalid recording-MBIDs:
- Some MBIDs are completely unknown or broken. These should be scrutinized individually.
- Our tests claim these issues occur 5.45 times per 10000 rows.
-
Unknown Issues:
- We expect more issues in the MLHD, especially as a subset of the Invalid recording-MBIDs mentioned above.
Project Goals:
To Ventriloquize the abstract:
The primary objective would be to create an updated version of the MLHD in the same format as the original, but with incorrect data resolved and invalid data removed.
To mark clearly, this is an exploratory project, and therefore the process would be highly dependent on hypothesis tests. We aim to follow an iterative, feedback-oriented process to explore potential options, and the details are subject to constant reassessments based on hypothesis tests and their results.
Steps Involved:
(A) Explore the MLHD data, find issues, explore methods to resolve these issues, and benchmark the performance of different methods for resolution.
(B) Implement a standard method in Python + PostgreSQL.
(C) If the performance is satisfactory, move to Spark Deployment. Else move back to step 1 and find other ways.
(A) Exploration
-
Randomly sample files from the MLHD, and list counts for how often issues occur in each sample.
- E.g.:
- E.g.:
-
The results of these analyses determine the next steps.
- e.g. The results claim 0 track-MBIDs made it into the recording-MBID column.
- We can either declare the hypothesis false, or try to look for more evidence in the dataset.
-
Processes Tackling Listed issues (so far):
-
Looking up recording-MBIDs:
- First and foremost we need to verify every recording-MBID in the dataset by cross-checking it in the “recording” table.
- This can be either done by querying the SQL table from a locally hosted instance of PostgreSQL containing the MusicBrainz database, or by loading up the “recording” table into RAM with our Python code.
This is a possibility since we have access to ~128GB RAM in our private server “wolf”.
-
Conflated artists:
- Baseline, we might need to use the recording-MBID to find the recording artist. Then use this newly found MBID to check if it’s equal to the artist-MBID in MLHD… and repeat it, for 27 bn rows. However, this process can be optimized using caching and tracking conflated artists.
- Option 2: Get the plaintext recording-name & artist-name for each row, and pass them through the artist/recording mapper on the MusicBrainz database… 27bn times.
- Option 3: Explore the complete MLHD dataset and lookup text names for all artist-MBIDs. Now store artists with similar names together. Finally, verify artist-MBIDs & recording-MBID relation for all these limited IDs.
- Option 4: Explore more options?
-
non-canonical recording-MBIDs:
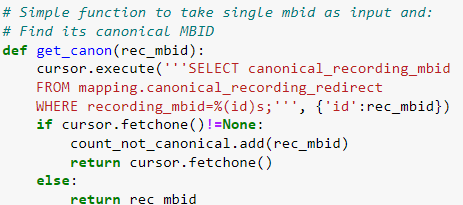
- Pass a batch of rows through the mapping.canonical_recording_redirect table
and fetch canonical recording MBIDs for every row.
- Pass a batch of rows through the mapping.canonical_recording_redirect table
-
Alternative (redirectable) recording MBIDs:
- If a batch of rows isn’t present in the recording table, pass a batch of rows through the recording_gid_redirect table and fetch the latest release-MBID if any.
-
track-MBIDs being mistaken for recording-MBIDs:
-
If a recording-MBID isn’t present neither in the recording table nor in the recording_gid_redirect, check if it’s present in the track table.
-
If it’s a track-MBID, record the MBID and replace it with a fitting recording-MBID.
-
-
Invalid recording-MBIDs
- These MBIDs would have to be dealt with separately.
- E.g. MBIDs are each 36 char UUIDs. Some of these unlisted issues could be caused due to improper formatting of these IDs. In such cases, these MBIDs should be dropped.
-
Rows with absent data
- ~58% of all logs on MLHD have full data (i.e. MBIDs for all 3 entities.) & 93% of the logs have at least the artist-MBID.
- However, logs without recording-MBIDs are less useful for applications like recording recommendations. In such cases, we’d have to decide, whether to keep such logs in the final version or not.
- With the MLHD, we expect the calculation of “listening sessions” based on how many songs people listen to in a row. If we decide on dropping less informative rows, data for such sessions could be hampered.
-
-
Parameters to Evaluate the data:
- Number of recording-MBIDs not present in the MB recording table.
- Number of track-MBIDs in recording-MBIDs.
- Number of non-canonical recording-MBIDs.
- Number of redirects.
- List of MBIDs that don’t fall into any above categories.
- The number of unknown issues.
- The number of bad rows per 10000 rows.
- List of Artists creating conflicts.
Cleanup Process Flowchart (basic):
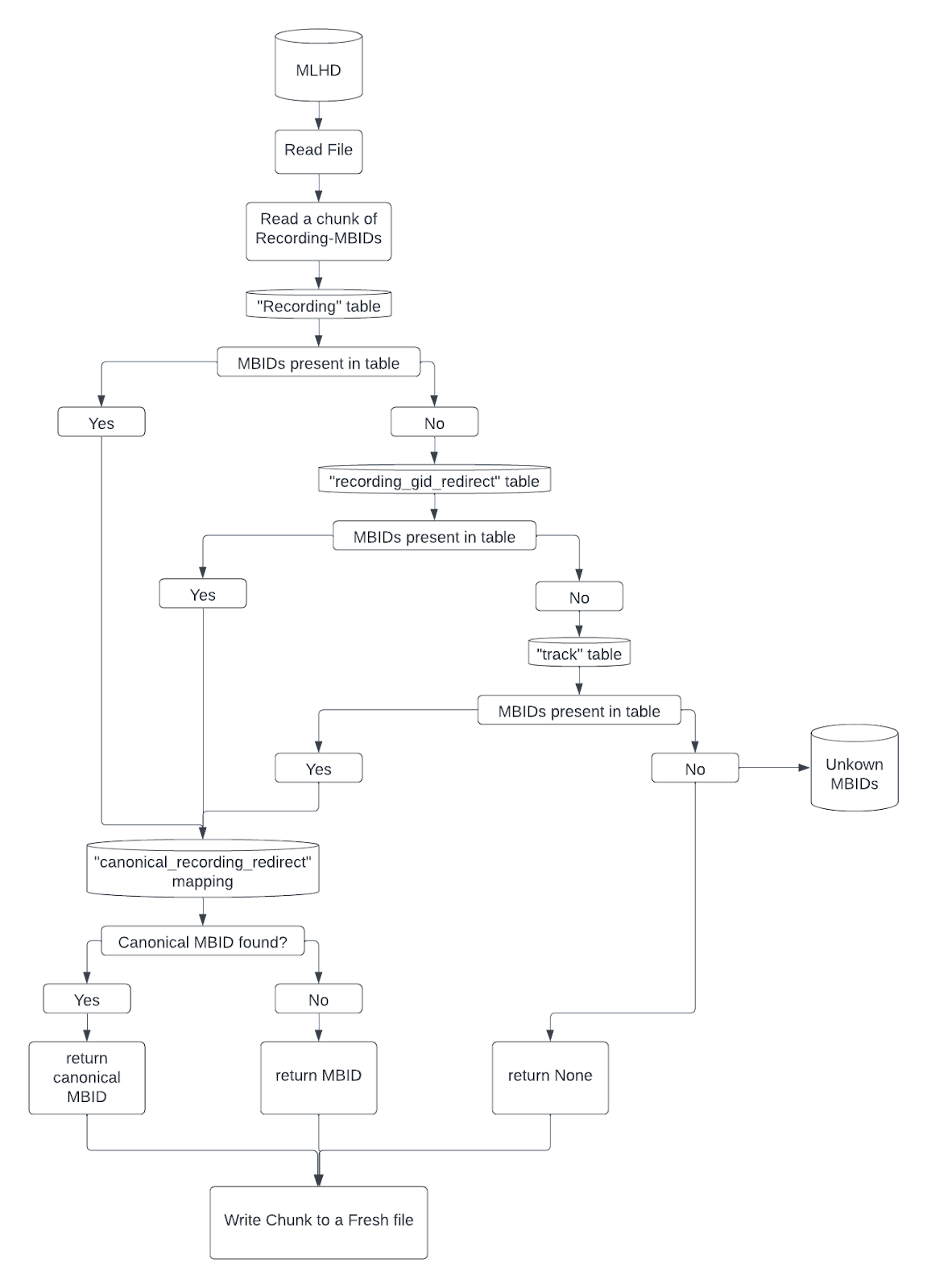
The above flowchart represents our expected basic algorithm for scrutinizing a chunk of recording-MBIDs from the MLHD.
It can be roughly broken down into the following process:
- Check if MBIDs are present in the “recording” table on the MusicBrainz Database.
- If not, check if the MBIDs are present in the “recording_gid_redirect” table on the MusicBrainz Database.
- If not, check if the MBIDs are present in the “track” table on the MusicBrainz Database.
- If not, mark the MBIDs as “Unknown”
- Now pass all the “Known” MBIDs through the “canonical_recording_redirect” mapping table on the MusicBrainz Database.
- Now, a series of recording-MBIDs that we originally passed through the algorithm should be either canonical, or unknown.
Now these unknown MBIDs should be processed separately.
(B) First Working Model with Python
-
Start translating the Jupyter Notebook code into production-ready python code.
-
Optimizations:
- Dask DataFrames are processed in chunks. Find the optimal chunk size for Dask Dataframes and SQL queries.
- Load up relevant SQL tables into memory for faster lookups, instead of database lookups.
- Split the Jupyter notebook into modules.
- Write unit tests.
- Explore LLVM-based compilers like Numba especially for optimizing loops.
-
Analyze a small chunk of MLHD data, and collect statistics for bad data.
(C) Transport the script from Python to the Spark Cluster
If the last step is successful, move to Spark Deployment.
- Most of the lookup items that we’ve specified in the proposal can be done quickly enough in python (such as looking up canonical-recording-MBIDs, and recording-MBIDs-redirects).
- However, If we find many conflated artist MBIDs in the dataset, this is probably the point at which we might need to get faster tools such as Spark.
Procedure:
-
Import missing MLHD datasets into the Spark cluster.
-
Port the Python code & queries into Spark.
-
If the code is working well with 1 chunk of code, start scaling it on Spark for large deployment.
- We can use Spark’s parallel computing abilities to process the MLHD data in distinct chunks.
- This can be especially useful in resolving the “conflated artists” issue, and for verifying the recording-MBID for each log in the MLHD.
- This can also be used to quickly browse through the MLHD and find similarly named artists in order to reduce the possible sample space for resolving the artist conflation issue.
-
Schedule & Monitor Batches to process MLHD data on Spark.
(+) Deliverables
-
The primary objective is to create an updated version of the MLHD in the same format as the original, but with incorrect data resolved and invalid data removed.
- Please refer to the above pages for the current structure of MLHD.
-
Algorithm for Cleaning up a chunk of data and recording bad data.
- Ideally, this should be a fast and efficient Python + PostgreSQL Deployment.
-
(If the previous step DOESN’T work well) Spark Deployment.
-
(If the previous step works) Process & Warehouse some chunks of the data.
-
(Optional) Detailed analytics and statistics on bad data.
- All the changes made in this new version should be well documented and the statistics for the updated data should be recorded.
- Some of these pointers have been declared on page number 9.
-
(Optional) Documentation / Blog detailing the methodology & findings from the MLHD data (for future projects)
Why would I like to work with MetaBrainz?
Along with my whole teen life revolving around technology, I’ve spent quite some time trying to learn the ins and outs of making music and consuming music like a maniac.
Throughout this journey, MetaBrainz has been an omnipresent helping hand; be it with tagging & identifying downloaded music with Picard, or powering sites like last.fm even before I knew the name MetaBrainz!
About 6 months ago, I was running an analysis project on my scraped last.fm data. And to no one’s surprise, I discovered that the metadata that came with the scrobbles was pretty limited, even after pairing it with the Spotify API.
Even since my music production days, I’ve been bugged by the lack of standardization in the music metadata space. Now, even more so since I’ve completely indulged myself around this domain. Thankfully, the MetaBrainz community has been infinitely helpful throughout this journey and at this point, I’d be more than happy to give back something, and learn a lot more about this very niche domain that interests me; especially when my goals & values seem to align really really well with the community. I plan on continuing my contribution to MetaBrainz well after my tenure with GSoC ends.
Project Timeline:
A detailed 12 Week timeline for the duration of Google Summer of Code.
Community Bonding Period (May 20 - June 12):
-
Get to know mentors and fellow GSoC candidates.
-
Catch up on relevant documentation & research articles.
-
Find specific seniors to guide in specific situations.
(currently: alastairp, lucifer, & mayhem for database, programming, and Spark related issues.) -
Complete the IBM Databases and SQL for Data Science with Python Course with honors.
-
Learn and set a basic workflow in Spark.
(refer to the IBM Introduction to Big Data with Spark and Hadoop Course)
Phase 1 (June 13 - July 25):
-
Week 1 (June 13 - June 19)
- Data Exploration (MLHD, relevant MusicBrainz tables on PSQL)
- Refer to the “Project Goals” section for more info.
-
Week 2 (June 20 - June 26)
- Setup complete env with:
- SQL connection w/ psycopg2 (get advice for SQLalchemy as well)
- Dask dataframes + import routines.
- random selection of logs from a chunk for even data.
- Setup complete env with:
-
Week 3 (June 27 - July 03)
- Write routines to fix listed issues (except conflated artists)
-
Week 4 (July 04 - July 10)
- Process data in batches with PSQL Instead of loops.
- Explore and pick an optimal batch size for Dask dataframes & PSQL queries.
- 9th, 10th June Exams.
-
Week 5 (July 11 - July 17)
- Try and find logs with artist conflation issues & other unknown issues.
- Try different methods to resolve this.
Phase 2 (July 25 - Sept 05):
-
Week 6 (July 18 - July 24)
- Start Coding the final algorithm into Python Modules, get advice from alastraip.
-
Week 7 (July 25 - July 31)
- Get Spark Basics right, get advice from Mayhem & Lucifer
- Import Missing MLHD & MusicBrainz DB datasets into Spark
-
Week 8 (Aug 01 - Aug 7)
- 6th & 7th Aug examination break.
- Translate Python and SQL code into Spark. Use previously written modules wherever possible.
-
Week 9 (Aug 08 - Aug 14)
- Translate Python and SQL code into Spark. Use previously written modules wherever possible.
-
Week 10 (Aug 15 - Aug 21)
- Translate Python and SQL code into Spark. Use previously written modules wherever possible.
-
Week 11 (Aug 22 - Aug 28)
- Deploy code into Spark, scale and schedule batches to process the MLHD dataset.
-
Week 12 (Aug 29 - Sep 05)
- Deploy code into Spark, and scale it up
- Schedule & monitor batches to process the MLHD dataset.
Some Questions as asked on the Official MetaBrainz GSoC template:
-
Tell us about the computer(s) you have available for working on your SoC project!
- I am currently rocking a Dell Inspiron 11 3148
(i3 4030U @ 1.9GHz ; 8 GB RAM) as my primary machine. - Thanks to the amazing MetaBrainz community, I also have access to the community server “Wolf”, and I’ve also previously worked with “Bono”.
- I am currently rocking a Dell Inspiron 11 3148
-
When did you first start Programming?
- I started out in 6th grade by writing batch scripts on windows
- Moved on to cybersecurity in 9th grade
- Took a pleasant turn in 10th grade toward music production
- Now for the past 2 years, I’ve been studying Data Science & AI, and its applications in the world of Music, Metadata analysis, feature extraction, and related Social Networks.
-
What type of music do you listen to?
- You can find my music taste here: snaekboi - ListenBrainz
- I have a weird obsession with Japanese rock, post-hardcore, Progressive-rock, Math-rock, Tech House, Progressive House, Hardstyle, Lo-Fi Hip-hop, Orchestral Music, Piano Solos, and a total hotchpotch of a lotta weird genres!
- E.g. (recording MBIDs):
cba64bc9-28cf-447e-9625-4f079c06ec23,
2259521d-11ab-4bde-95bb-0942b2f42e32,
256a6018-21d1-4de2-af70-3532206f5ee5,
f45fb199-97eb-4732-8c55-79185e22b457,
f2d5d66f-cf72-4e04-b913-9da2cfa1affb
-
What aspects of the project you’re applying for?
- I love working with Music Metadata and social networks, and I’m also getting my feet wet with Machine Learning.
- Therefore, I am most interested in MusicBrainz, ListenBrainz, & AcousticBrainz.
-
Have you ever used MusicBrainz to tag your files?
- Yes, I love MusicBrainz Picard, and I’ve used it to tag every single track in my 20 GB offline music library

- Yes, I love MusicBrainz Picard, and I’ve used it to tag every single track in my 20 GB offline music library
-
If you have not contributed to open source projects, do you have other code we can look at?
-
Yes, I am currently working on a personal project that aims to scrape data from Last.fm/ListenBrainz, apply my own computations with the MusicBrainz/Spotify API, and provide the user a rich set of world class metadata features for personal-use/analysis/archival.
-
You can find the project here on GitHub: GitHub - Prathamesh-Ghatole/lastfm-scraper: Scrape your last.fm data. · GitHub
-
I’ve also started roughly analyzing & cleaning some parts of the MLHD here: GitHub - Prathamesh-Ghatole/MLHD-Dataset-Testing: A testing repo for checking and processing the ListenBrainz Music Listening History Dataset! · GitHub
-
-
What sorts of programming projects have you done on your own time?
-
My interests mostly lie in the domain of Data Science / Data Engineering / AI, therefore most of my projects are Data Analysis and Machine Learning Oriented.
-
You can find some of my personal projects on my GitHub profile. (linked on page 1)
-
-
How much time do you have available, and how would you plan to use it?
-
I’d be able to find 40 hours weekly for my GSoC activities with MetaBrainz.
-
I love to take on new challenges, and I’ve gathered up a lot of responsibilities. However, I’ve taken a 4-month downtime out of my extra responsibilities including club work, and other extracurricular activities.
-
However, given my peculiar dual degree scenario, I’d have to take some time off for my examinations around the following dates:
5th June, 10 July, 7th Aug.
-
About Me:
Hi, I am Prathamesh, an aspiring Data Scientist with a sheer obsession for music & computers.
Back in 6th grade, I started tinkering around with computers and developed a severe passion for technology, making it a highlight of most of my teen life.
5 years ago I developed a similar passion for making & consuming insane amounts of music.
Given my 3+ years of experience in Music Production, playing Piano, & Audio Engineering under my artist alias “SNÆK” & a life-long love for computers, my passion in the world of audio and technology has now convolved into a passion for Data Science and AI for audio involving Information Retrieval, Musicology, & Digital Signal Processing, and related Social Networks!
As a 2nd-year undergrad, I am currently pursuing degrees in Data Science → IIT Madras & AI → GHRCEM Pune respectively.
Skills:
*Proficient: Python, Git, Linux, Pandas, Dask, REST API Scraping, Numpy, Plotly, Seaborn
- Basic: SQL, Postgresql, MS Azure & IBM Cloud, scikit-learn, NLTK.
- Interested in learning: Advanced SQL, Spark.
-
Relevant Certifications:
- Git from Basics to Advanced - Practical Guide for Developers - Udemy
- Applied Data Science Specialization - Coursera
- Introduction to Data Science in Python
- Applied Plotting, Charting, and Data Representation in Python
- Applied Text Mining in Python
- Python 3 Specialization - Coursera
- Python Basics
- Python Functions, Files, and Dictionaries
- Data Collection and Processing with Python
- Python Classes and Inheritance