A Job Running Client for AcousticBrainz
Allowing users to run jobs on their own machines and submit the result.
Introduction
AcousticBrainz allows the users to create dataset and run machine learning jobs on it and view the best results. Currently the jobs run on the AcousticBrainz server and sometimes the servers get too busy and even take very long to process a job due to a long job queue. This project is aimed at building a client that will enable the user to run job on their own machine and then submit the result to the AcousticBrainz server for themselves and other users to view.
Personal Details:
Nickname: Kartik Gupta
Irc Nick: kartikgupta0909
Email: kartikgupta0909@gmail.com
Github: kartikgupta0909 · GitHub
Proposal:
We will be building a Linux client to allow the users to run the machine learning jobs on the datasets on their machine and then submit the results on the server. This will include the following components:
1.System Setup: We need to install various libraries such as Gaia2, Yaml, Google-protobuf and Screen. Once the dependencies have been installed the user will be able to run a python script through command line.
2.Preparing the job on the AcousticBrainz server to be picked up by the client: When the user wishes to run a job on a dataset, and once he clicks on the evaluate link for a dataset he will be given an option of running the job on the AcousticBrainz server or his own machine. If he chooses to run it on the AcousticBrainz server, then the dataset job will be added to the server queue and if he clicks on the “Evaluate on your machine” button (as shown below), then he will be given an authentication token for that dataset.
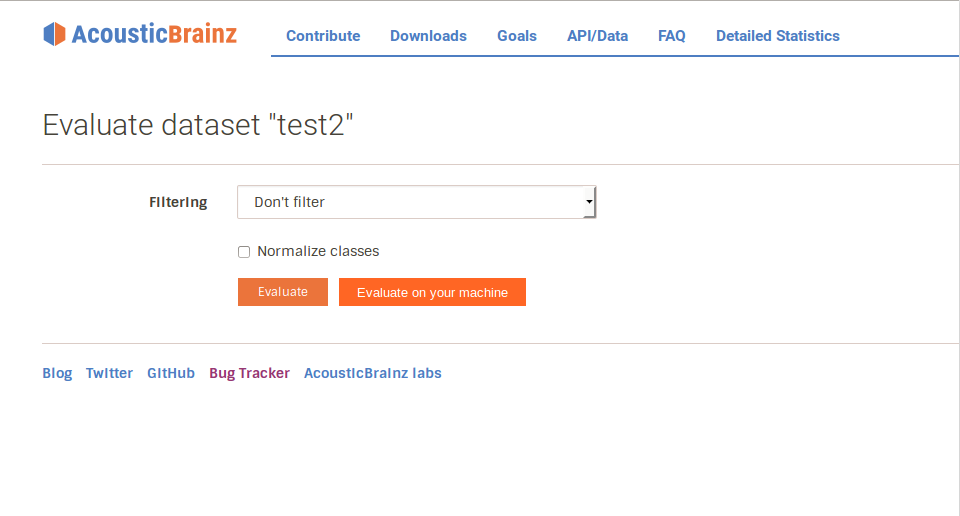
An option for the user to choose to run the job on his machine
If they click on the “Evaluate on your machine” button they they are taken to a page which contains the job id and the authentication token for that job. Once the user sees the authentication token, this token along with the dataset id will be passed to the client script for running the Job. Only the owner of that dataset will be able to see this authentication token.
Once the AcousticBrainz server recieves a request from a client with dataset id and authentication token as arguments it will verify if that authentication token is issued for that dataset or not. And if yes then it will send the dataset as a single protobuf file containing all the data required to run the job (including the low_level data of all the songs in the dataset). We are not using Raw Json as it might take much more space than protobuf and hence increasing the network load. Also the server will return the job_id.
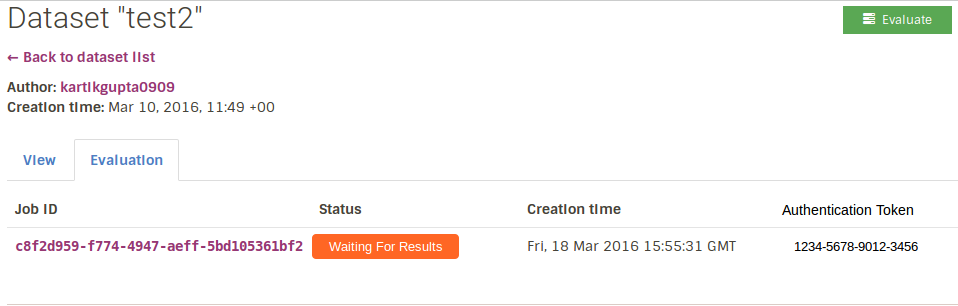
3. Retrieving the dataset: Once the dataset has been recieved by the client as a protobuf file, it will be deserialized and used for the job.
4. Starting the job: Once we have the deserialized data for the dataset, we can start the job. We will be having a gaia_wrapper module which will have all the required functions which will call the neccessary functions of the library gaia2. We will pass the data to this module which will run the job on it. The job will be started using Screen to keep the job isolated from the other processes and to keep it running even when the user logs off.
5. Submitting the results: Once then job is completed and the results have been saved, they will be sent back to the server along with the dataset id, job_id and the authentication token. On the server side the authentication token will be verified for the job_id. If its correct then the format of the recieved file will be checked against a standard format of the result file. If the format is correct the server will accept the results sending back a success token to the cilent. Once the server had recieved the result file it will update its database to store the result for that dataset and also change the status of that job to “Done”.
Milestones:
Milestone 1 (Week1 - Week 2): Writing the Installation Script.
Milestone 2 (Week 3): Giving an option to the user to run the job on his machine and generating an authentication token for it.
Milestone 3 (Week 4): Client makes a request to the server with the dataset id and the authentication token.
Milestone 4 (Week 5 - Week 6): Writing the server side code for recieving the request from the client and process it (authentication, retrieving dataset details etc) and then serialize the data into protobuf and then sending it to the client.
Milestone 5 (Week 7): Recieving the datafile on the client side and deserializing it.
Milestone 6 (Week 8 - Week 9): Starting the job as a process on Screen (Will include writing gaia wrappers).
Milestone 7 (Week 10): Client submitting the results to the server.
Milestone 8 (Week 11): Server accepting the results(also authenticating) and returning a success code to the client.
Error Handling:
Since the client and the server need to communicate to each other regularly, we need to take care when one of them goes into an error condition and the other one needs to be informed. Some of the possible error conditions are:
1.The dataset_id or the authentication token passed to the server from the client wasnt correct. Then the server should return an error code which the client understands. (This will be handled in milestone 4)
2.The protobuf file might get corrupted during transmission from the server to the client. We need to send the file hash along with the file to handle this kind of error (This will be handled in milestone 4).
3.The result file might be corrupted: Send a file hash (This will be handled in milestone 7).
4.The result file might not be in the expected format: Indication of some malicious activity. If the format of the file is not expected then the server will not accept the file and send a failure code to the client. (This will be handled in milestone 8)
What will the community get from this project?
1.It will reduce the load on the AcousticBrainz server significantly
2.The users wont have to wait very long for the result of their jobs on their datasets because the queue is too long on the AcousticBrainz server.
3.It will be a new kind of contribution from a user to the Open Source Community where a naive user (who might not be able to contribute code or money) contributes computation power to the Open source organisation instead.
Details About Myself:
1.Tell us about the computer(s) you have available for working on your SoC project: I ll be having a personal laptop with Ubuntu 15.04 and Windows 10 installed.
2.When did you first start programming : I started programming 3 years ago when I started my Btech in Computer Scienc.
3.What type of music do you listen to? (Please list a series of MBIDs as examples.): I mostly listen to EDM music. Examples: c0dccd50-f9dc-476c-b1f1-84f00adeab51,d08ab44b-94c8-482b-a67f-a683a30fbe5a,5251c17c-c161-4e73-8b1c-4231e8e39095,2618cb1d-8699-49df-93f7-a8afea6c914f
4.What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most: This is one of the first projects to store low level data for music and run machine learning jobs on it. (I dont know of any other). Since my reaserch is on machine learning in music this project interests me.
5.Have you ever used MusicBrainz to tag your files: Only for the purpose of uploading them to the AcousticBrainz server.
6.Have you contributed to other Open Source projects? If so, which projects and can we see some of your code: Yes I have contributed to Mozilla Release Engineering, AcousticBrainz and Scilab. I have successfully completeted a Gsoc project in Scilab in 2015 (https://codereview.scilab.org/#/q/owner:kartikgupta0909%2540gmail.com+status:merged).
7.What sorts of programming projects have you done on your own time: System programming, machine learning,Data sciences.
8.How much time do you have available, and how would you plan to use it: On week days I can devote 5 hours a day to this project and on weekends I can give upto 8 or maybe 10 if required.
9.Do you plan to have a job or study during the summer in conjunction with Summer of Code: I plan to continue my usual research work during this time along with Gsoc if selected. Usually research takes around 2-3 hours of my daily time. I have a vacation of my college during the Gsoc period hence no obligations from college.
 I’ve already linked from the GSoC website to this post. Your proposal sits at
I’ve already linked from the GSoC website to this post. Your proposal sits at 