As I’ve gotten further with what I’m sorting down, working on here- the differentiation between the two ‘sides’ has become an awful lot more clear.
First, yes, it may sound like a big huge D’oh! moment, but For the longest time I absolutely did not realize that you could even save stuff from the Left side, that you had to run it over to the right, which meant looking up releases manually when you were dealing with a VA release of any kind.
…because otherwise Picard was pretty much guaranteed to match those singles up to an album by artist way more than the compilation album. Which of course, you can see where that is going to go.
Part of the reason I have so many files/different directories of stuff. “Okay. that was a bad idea sorting wise, so I’m going to just keep this all until I have time to do it ‘right’.”
As in, yes, I do keep a backup of everything on a separate drive / volume and use rsync.
But once I figured out that I can save things from the left side, well then, that Mass of the Messes source side has gotten a lot more manageable.
So, with that, I’ve been grouping stuff and changing the filenaming script content accordingly, mostly when dealing with some huge sets of numbered files. (Think a week’s worth of a particular radio stream ripped into individual tracks … into the 10,000’s of tracks per ‘album’) that never got a Compilation Tag initially. So. OMG. But I can ‘gather them’ up again this way.
So, while the absolute goal with Picard was to make a tool to help sort data towards encouraging data submission to the DB, though even with intent by design, it is still very practical to save from the left when the DB does not apply. At least at that point in the flow of sorting.
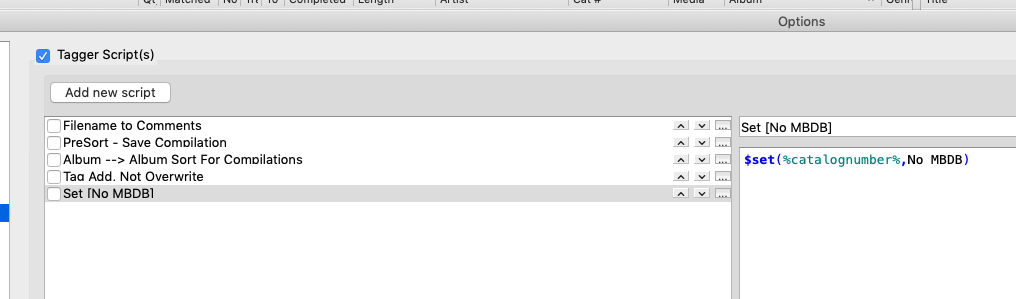
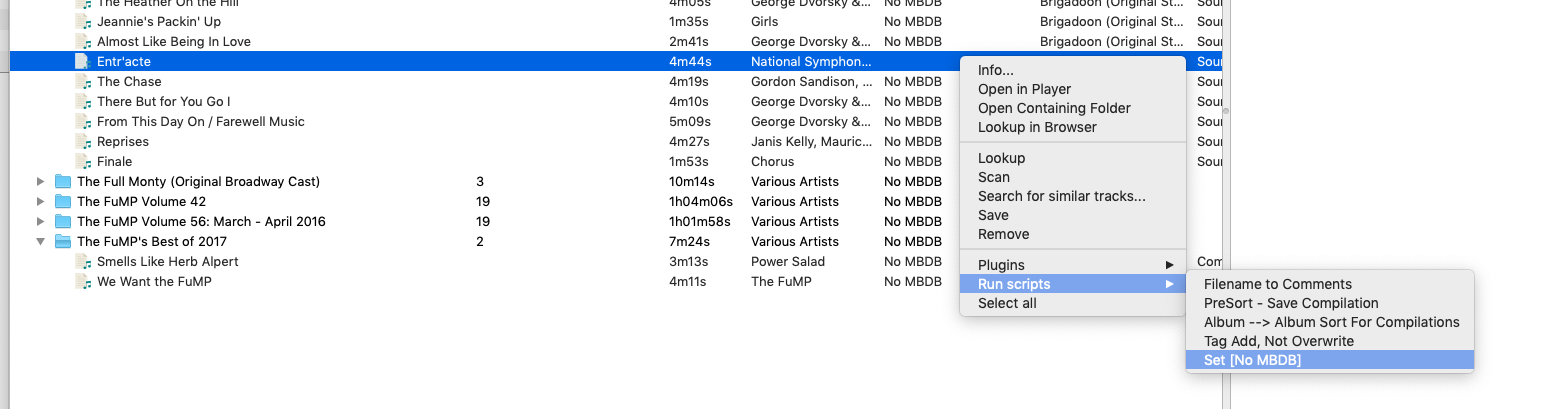
That said, I can apply a script via right-click execute. But obviously the naming portion of the script can not be used towards path destination in that form as there is no way to apply a specific script to the saving process. Leaving one to go and change the contents of the naming script when something different is desired at that point / with that particular data.
So, if there were a way to connect a tagger script to saving on demand, as an exception to the default naming script.
Maybe I can figure some back end hack out for this, too  Two weeks ago I’d have never imagined. I’ve picked up Python quite well, though not enough to go from scratch by any means, but following and using whats there as examples works great and can only lead to the point of being able to start from a blank slate. Because yeah, “Hello World” just doesn’t do it for me. Except, for checking to see that the installation was done correctly.
Two weeks ago I’d have never imagined. I’ve picked up Python quite well, though not enough to go from scratch by any means, but following and using whats there as examples works great and can only lead to the point of being able to start from a blank slate. Because yeah, “Hello World” just doesn’t do it for me. Except, for checking to see that the installation was done correctly.
…and if Picard could import a list of tags from a csv and apply them to files by name… Oh that would turn this amazing toolbox of functions into the whole tool truck.
But right now… just being able to use an alternate set of rules for saving would go a long ways more.
e.g.: Maybe I can come up with something.