Personal information
Nickname: Adesh Pandey
IRC nick: adesh
Email: pandeyadeshdelhi@gmail.com, adesh14004@iiitd.ac.in
GitHub: adeshp96
PROPOSAL: Optimize Database Access In CritiqueBrainz
OVERVIEW:
PART 1: OPTIMIZING PERFORMANCE BY REPLICATING MUSICBRAINZ DATABASE
Presently, CritiqueBrainz heavily relies on MusicBrainz database to serve extra entity related information along with the reviews. For this CritiqueBrainz uses the web service provided by MusicBrainz. All reviews need some extra information supplied along with it for the entity reviewed. But this creates a significant slowdown whenever CB needs to show many reviews on a single page, since each of the request-response to and from the MusicBrainz database server takes time. Presently MusicBrainz metadata is retrieved by the library musicbrainzngs with the interface module “musicbrainz”.
The solution is to replicate the MusicBrainz database at the server end of CritiqueBrainz and set up live feed to ensure the data remains in sync. Live feed would be set up by setting up musicbrainz mirror server. After this, all the methods in musicbrainz module need to be redefined to make use of the local copy of database.
The project would remove a major dependency on the musicbrainz database server and make development for CritiqueBrainz easier (also for Part 2 of this project).
PART 2: CONVERTING ORM IMPLEMENTATION INTO RAW SQL:
CritiqueBrainz uses SQLAlchemy ORM to interact with the database. Though this internally handles much of database interaction, but it adds several constraints and creates the need to write complex queries which are harder to maintain. This part of the project will try to remove the dependency on SQLAlchemy ORM which in turn would lead to less complicated queries and hence faster database access and easier management.
The database queries through SQLAlchemy ORM are spread over several models and views (in data, frontend and ws). Under the project, the existing models and views will be modified to use suitable raw SQL queries.
SQLAlchemy Core would be used to set up the connection and execute the queries. It internally uses psycopg2 database adapter.
IMPLEMENTATION:
PART 1: OPTIMIZING PERFORMANCE BY REPLICATING MUSICBRAINZ DATABASE
Initially, the MusicBrainz database needs to be set up at the CB server’s end and the database dump imported. Then, musicbrainz mirror server needs to be setup and configured for live feed (i.e. configured with REPLICATION_TYPE=RT_SLAVE). For hourly syncing, LoadReplicationChanges would be scheduled to run every hour which will sync the local database with the remote MusicBrainz database.
Database schema for MusicBrainz database:
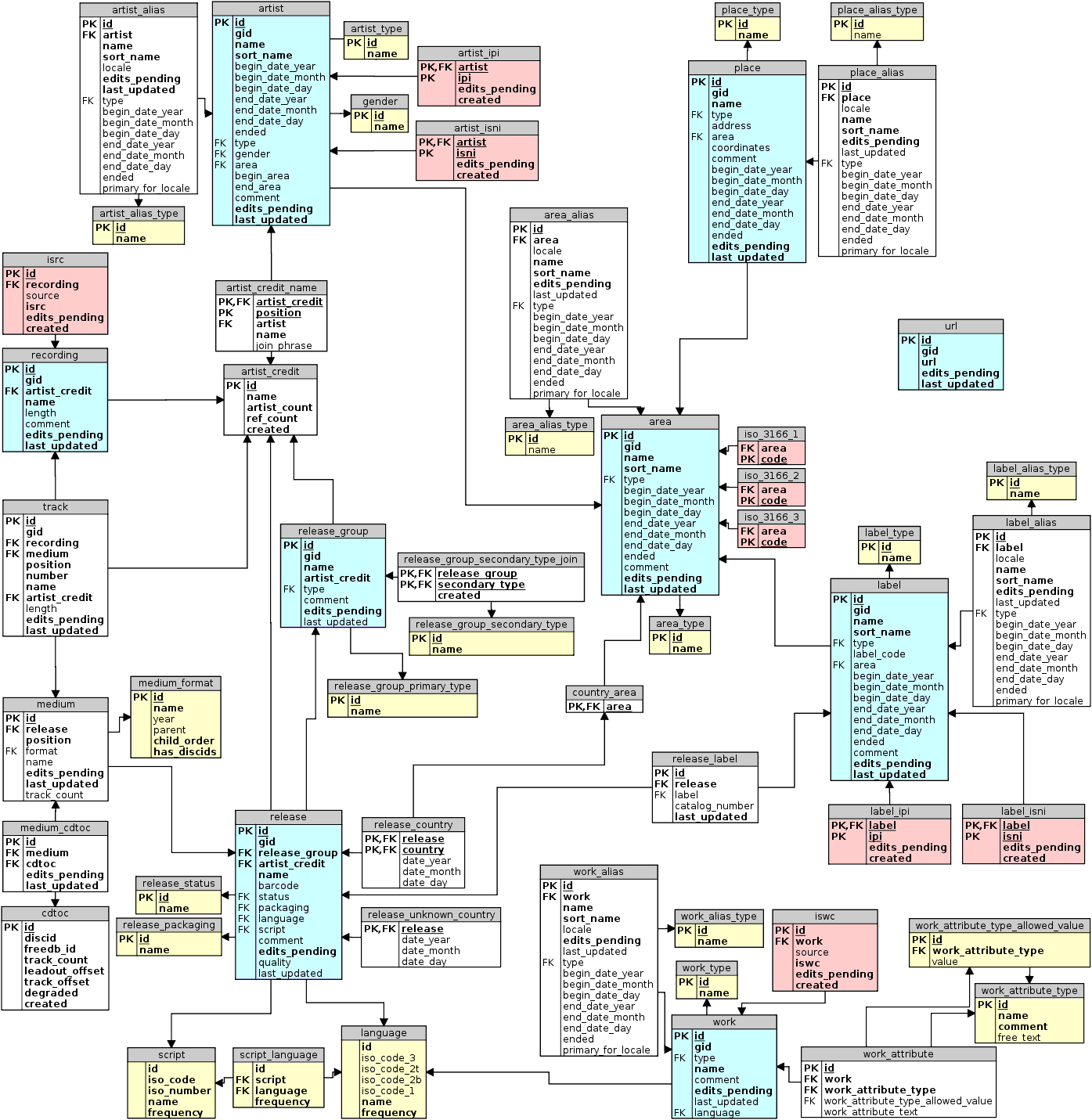
After this, CritiqueBrainz need to be set up to use the dump. For this, the methods, relating to MusicBrainz web service access, defined in external module musicbrainz module need to be rewritten (to use the local database), namely:
• search_release_groups()
• search_artists()
• search_events()
• browse_release_groups()
• get_artist_by_id()
• get_release_group_by_id()
• get_release_by_id()
• get_event_by_id()
All the above methods would be redefined in raw SQL, perhaps using SQLAlchemy Core for connection or directly psycopg2. I would go about defining these methods in SQL as follows:
• search_release_groups(query, artist, release_group, limit, offset)
The function doesn’t consider “query” if any of the artist or release_group is specified (it indirectly uses _do_mb_search () which works like that).
If a query is specified then we simply search for it in “release_group” table by the name. The same applies if a release group has been specified. If an artist is specified, then we can find that artist’s id from the given name. Then if only 1 artist remains we can use browse_release_groups () to obtain the release groups. Or else if multiple artists are found (which will mostly be the case), do their join with artist_credit_name on artist.id==artist_credit_name.artist. On the resulting join we further join with table artist_credit on artist_credit_name.artist_credit==artist_credit.id and then another final join with release_group on artist_credit.id==release_group.artist_credit. This finally gives us the release group for the artists. We include only the results within (offset, offset + limit) range and return.
• search_artists(query, limit, offset)
This will essentially be a filtering in the artist relation over the provided query by name. Then combining the results into a list and returning it. Include only results within (offset, offset + limit).
• search_events(query, limit, offset)
Similar to the above. We will filter on the relation “event”. Combine into a list and return it.
• browse_release_groups(artist_id, release_types, limit, offset)
First we need to find the id of that artist by filtering “artist” according to the given gid. Then, we need to filter “artist_credit_name” for the obtained id. From the obtained result we then need to find the artist_credit from “artist_credit” relation. For this we can join the result obtained earlier with “artist_credit” on artist_credit_name.artist_credit==artist_credit.id. Then to finally get the release_group we need to join this result with release_group relation on artist_credit.id==release_group.artist_credit. Then, we can filter on the release_types and return the result as a list.
• get_artist_by_id(id)
//possible includes: url-rels, artist-rels
First we will filter for the “id” in the artist relation. Then search for the obtained “id” of the artist in the table “l_artist_url” and “l_artist_artist” for url-rels and artist-rels respectively.
• get_release_group_by_id(id)
//possible includes: ‘artists’, ‘releases’, ‘release-group-rels’, ‘url-rels’, ‘work-rels’
Filtering release_group for the given gid gives us the release_group information. For include on artists, search in artist-credit according to the artist_credit found in the release group information. To obtain the releases, we need to filter release table by the given gid on its release_group (FK) attribute. To obtain release-group-rels we filter by gid in l_release_group_release_group. For URL filter l_release_group_url by gid. Similarly for work-rels.
• get_release_by_id(id)
//possible includes: ‘recordings’, ‘media’, ‘release-groups’
Filter on the release table for given gid. To get the media we need to filter table “medium” according to the id of the release obtained. To get the release group we simply search for the found release_group attribute, in the table “release_group”. To obtain all the recordings, filter for the found medium’s id in table “track” on attribute medium (FK). This will obtain all the tracks associated with the media. Then, join the result obtained with recording table on track.recording==recording.id
• get_event_by_id(id)
//possible includes: ‘artist-rels’, ‘place-rels’, ‘series-rels’, ‘release-group-rels’, ‘url-rels’
This can be done by filtering on the event relation by the given gid. All includes can be obtained by filtering for the obtained id on l_event_artist, l_event_place, l_event_series, l_event_release_group, l_event_url.
The methods would be redefined by using the above logic and using raw SQL.
I will modify the definitions one by one and test after completing any method.
In effect, I intend to define two different modules for servicing queries related to MusicBrainz database:
- A module that defines these methods so as to use the MusicBrainz web service (and not the local MusicBrainz database, even if present). This module is going to be the present version of external musicbrainz module.
- A module that will have these methods redefined to use the local MusicBrainz database. The idea of SQL queries for these methods have been described above in detail.
Providing both the modules is essential in case of development when one cannot download the entire MusicBrainz database dump.
Which of the above modules will be used during runtime would be specified in the configuration. Then all the function calls to the MusicBrainz database usage will be mapped to one of the above two modules depending on the configuration specified. I will define another module that will manage this mapping depending on the configuration. All the functions will call this third module’s apt method for database querying and then the method would, in turn, call the apt method of the above listed 2 modules depending on the configuration specified. So, total 3 modules for servicing the database queries:
- Module 1: To service database queries by MusicBrainz web service.
- Module 2: To service database queries by using the local database dump.
- Module 3: To decide whether to call Module 1 or Module 2 depending on the configuration. Note that Module 3 will be the interface for all other modules to interact with Module 1 and Module 2.
How to handle batch processing when loading info about multiple entities?
The only need for batch processing arises when we need to show multiple reviews on a page (defined in “review” view). This is presently handled by multithreading by get_multiple_entities(entities) which in turn indirectly relies on get_event_by_id () to get the job done for each review. So to do this job in batch I will query the database for all the entities at once by their ID and return the result obtained. Specifically, in get_multiple_entities (), I plan to first group same entity types together (release_group or event) and then query both the table one by one filtering according to all the id(s) of that type at once. Then, combine the results and return.
PART 2: CONVERTING ORM IMPLEMENTATION INTO RAW SQL:
CritiqueBrainz database schema is as follows:
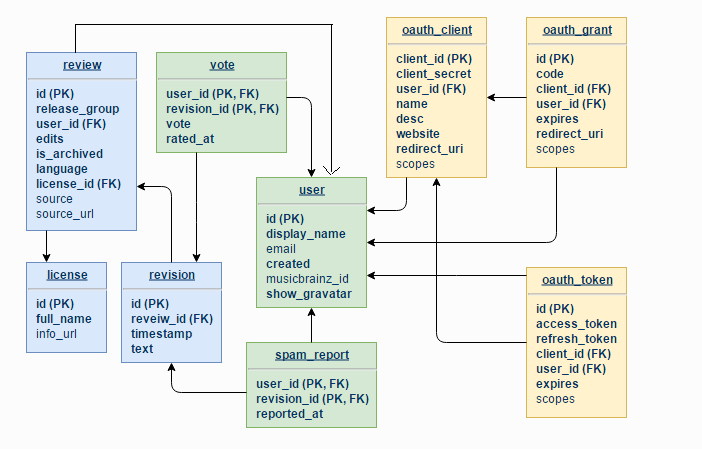
Any of the relationships/constraints earlier defined in the ORM would now be handled by the PostgreSQL by the definition of the relations.
All the class definitions would be removed and the method definitions would be modified to remove ORM usage. Even though the classes would be removed, the module structure (i.e. the presently existing models) would be still maintained. This would ensure the grouping of similar methods together.
I have looked in the various models of CB and the following models require modification:
● license
● mixins
● moderation_log
● oauth_client
● oauth_grant
● oauth_token
● review
● revision
● spam_report
● user
● vote
The changes in models would include class definition removal and method redefinition (in case there is an ORM based database access). The changes in views mostly include replacing an ORM database query with raw SQL database query (keeping in mind the new models).
While converting the queries, I will look for any alternative optimized query and if found, I will incorporate that instead.
I would be rewriting all the data models one by one. After I finish any model, I will modify all the usages of that model (in any other view or model), with testing after modifying every usage. This would be repeated for all the models.
The general approach would be to pick one of the models redefine the model completely to remove any use of ORM and replace it with a raw SQL query. When I am done with the redefinition I will track where all was this model being used, and make appropriate changes so that the new redefined model fits in.
Views rely on existing models in either of the two ways:
- Database queries based on ORM.
- By calling the user defined methods in the models.
Both the points will be solved model by model and one by one. Point 1 will be solved by replacing the existing ORM queries by raw SQL queries. To solve Point 2, the methods belonging to any of the model would anyway be redefined and then the view would use the redefined method instead of the earlier one. There might be a few extra changes required due to the new implementation of the models which would also be handled appropriately.
TIMELINE
Community Bonding Period
Study more about SQLAlchemy. This would be required to understand the existing queries even better and then think of a better alternative (if possible).
Understand more about the CritiqueBrainz code base. Learn more about the working of SQLAlchemy. Also, I would take up a few existing complex queries and convert them into raw SQL queries for practice.
I’ll also study AcousticBrainz project code once again for reference about the usage there.
I will also learn how MusicBrainz handles web service request and processes them.
Roughly Week 1 – Week 5 would be dedicated to Part 1. Week 5 - Week 12 would be dedicated to Part 2.
Week 1 – Week 3
Set up MusicBrainz data dump in my PC. Setup musicbrainz slave server to sync the database. Start working on rewriting the method definitions in external musicbrainz module.
Week 4- Week 6
Finish redefining the methods in external musicbrainz module. Somewhere around week 5, I will start with Part 2 of the project. I will begin rewriting the methods in the models. I’ll start rewriting with the crucial models like review and revision first (though it will take a lot of time). I intend to finish these first as they will help me optimize the core models and then focus on the rest. Any usage of a model would also be updated while working on that model.
Week 7- Week 9
Continue translating the leftover models. Along with testing them. I will be working on the models one by one and modify any usage of that model too (in any other model or view). This would mean updating views side by side. Coding for Part 2 of the project should be nearly complete in this period.
Week 10 – Week 12
Final testing for both models and views. Any dependency on SQLAlchemy ORM would be removed by now. Also start writing the documentation and testing the project as a whole. I would also rethink of various complicated SQL queries for optimization and update the code if necessary.
After Google Summer of Code
CritiqueBrainz will now perform a lot faster. I will stay active with CritiqueBrainz and keep fixing bugs whenever I am free (especially in my vacations).
Detailed information about yourself
● Tell us about the computer(s) you have available for working on your SoC project!
Compaq Laptop. Ubuntu 14.04. Dual boot with Windows. 4 GB RAM. Processor Intel i3 4010U @ 1.7GHz x 2 (+ 2 hyper-threaded cores). Intel HD Graphics 4400.
● When did you first start programming?
I started programming in 2012 in 11th grade.
● What type of music do you listen to? (Please list a series of MBIDs as examples.)
Songs by Taylor Swift (20244d07-534f-4eff-b4d4-930878889970), Eminem (b95ce3ff-3d05-4e87-9e01-c97b66af13d4), Avril Lavigne (0103c1cc-4a09-4a5d-a344-56ad99a77193), Taio Cruz (ba7d2626-38ce-4859-8495-bdb5732715c4)
• What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
I am mostly interested in the UI and making the project more appealing to the end user.
● Have you ever used MusicBrainz to tag your files?
Yes, occasionally.
● Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
I have fixed a few bugs in CritiqueBrainz itself.
Open PRs:
![]() Reviews filtered according to entity type by adeshp96 · Pull Request #16 · metabrainz/critiquebrainz · GitHub
Reviews filtered according to entity type by adeshp96 · Pull Request #16 · metabrainz/critiquebrainz · GitHub
![]() Review only search implemented by adeshp96 · Pull Request #15 · metabrainz/critiquebrainz · GitHub
Review only search implemented by adeshp96 · Pull Request #15 · metabrainz/critiquebrainz · GitHub
Merged PRs:
![]() Added note for drafts not being private and fixed ISE on reviewing event without place by adeshp96 · Pull Request #14 · metabrainz/critiquebrainz · GitHub
Added note for drafts not being private and fixed ISE on reviewing event without place by adeshp96 · Pull Request #14 · metabrainz/critiquebrainz · GitHub
![]() Added apt links to search results during review by adeshp96 · Pull Request #17 · metabrainz/critiquebrainz · GitHub
Added apt links to search results during review by adeshp96 · Pull Request #17 · metabrainz/critiquebrainz · GitHub
![]() If you have not contributed to open source projects, do you have other code we can look at?
If you have not contributed to open source projects, do you have other code we can look at?
I have forked the following repository from my college’s GitHub account for your reference:
GitHub - adeshp96/AP_Project
GitHub - adeshp96/notepad
● What sorts of programming projects have you done on your own time?
I learnt Android in free time and created a NotePad as part of learning it. I was also working on a single user forum to upload anything he/she is interested in. It’s not yet complete so, I intend to finish it later. As part of my academic work, I have also done many projects based on Java, created ARM Simulator (using C). As part of research work, deployed indicator functionality in an automated car (using ROS/C++).
● How much time do you have available, and how would you plan to use it?
I don’t have college or any other work during summers so I would have all the time to myself. I will dedicate up to 35-40 hours a week for GSoC. Preferably, a day off per week.
● Do you plan to have a job or study during the summer in conjunction with Summer of Code?
No. If selected for GSoC, I won’t have any other commitment for the summers except for a 4-5 days break when I need to visit my relatives.