ListenBrainz
ListenBrainz: A submission API compatible with Last.fm scrobblers
(This idea is an extention of one of the ideas mentioned on the ideas page)
Nickname: armalcolite
IRC nick: armalcolite
Time Zone: UTC/GMT +5:30 hours
Email: pinkeshbadjatiya[at]gmail.com
GitHub: pinkeshbadjatiya (Pinkesh Badjatiya) · GitHub
Recent Activity in LB: Fix for LB-13, LB-52, LB-66, LB-68, other bugs. - [ Pull Requests]
Project Details
Brief Overview
Listenbrainz is in state of infancy and needs some good amount of work to make it easy for users to use it. The submission method for users to submit their songs uses web-scraping (will use api, if my PR gets merged, hopefully) which is not reliable.
Their are a lot of applications and open-source projects that enable scrobbling to last.fm. In order to make them compatible for submission to LB, an api compatible with lastfm would be a good start. It would be an addition to the native LB api, giving it an additional upperhand.
Goals
- A submission API compatible with Last.fm scrobblers
Right now ListenBrainz has its own API documented at ListenBrainz documentation — ListenBrainz 0.1.0 documentation. The idea is to create a new web service, layered on top of that one which spoke the Last.fm API, so it could be used as a proxy for existing Last.fm clients.
It would be REST API similar to lastfm, allowing minimal but exact set of functionality.
-
Test suite for the New API
It would include tests written usingunittestmodule in python to ensure the API is not broken any any stage of development. -
Documentation for New API
The documentation of the working of API for ease of access and reference. -
Optional ideas
-
Export LB listens
Exporting ones personal listen history would be a good addition to the system. The format can be similar to the one which old version of lastfm gave or a new custom one, requires concent from mentors. -
Import lastfm backup
The previous version of lastfm allowed the users to create a download-able backup of their listens. So it would be a nice idea to allow the users to import their previous listen data as well. -
Test suite for native API
My understanding of native API has grown much better with my recent patches in scraper.js, porting it to use native API and export feature in LB. My idea is to create a testsuite for the existing Native API.
Implementaion Details
The current native API accepts a payload of the following json format. The import format can be one of the following, (single, playing_now, import).
"payload": [
{
"listened_at": 1443521965,
"track_metadata": {
"additional_info": {
"release_mbid": "bf9e91ea-8029-4a04-a26a-224e00a83266",
"artist_mbids": [
"db92a151-1ac2-438b-bc43-b82e149ddd50"
],
"recording_mbid": "98255a8c-017a-4bc7-8dd6-1fa36124572b",
"tags": [ "you", "just", "got", "rick rolled!"]
},
"artist_name": "Rick Astley",
"track_name": "Never Gonna Give You Up",
"release_name": "Whenever you need somebody"
}
}
]
The native api’s routes are as shown in figure,
Fig1. - The current native api interaction to submit a listen received from POST request.
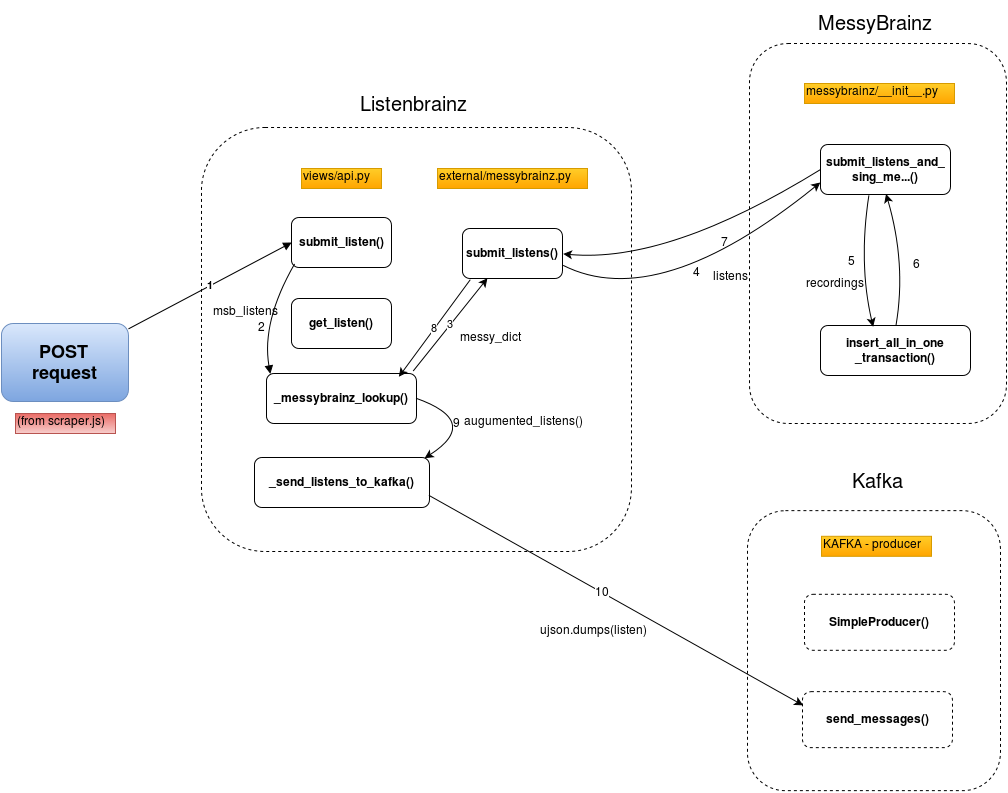
The NEW Addition to native api would be a new module with name as api_compat.py with root url as http://api.listenbrainz.org/1.0/compat/ with a blueprint
api_compat_bp = Blueprint('api_compat', __name__)
This would keep the existing systems intact and would not conflict with the existing implementation details.
The design of the new module would be as follows.
Fig2. - Shows the new addition to native api in the LB system, and the new routes which needs to be created.
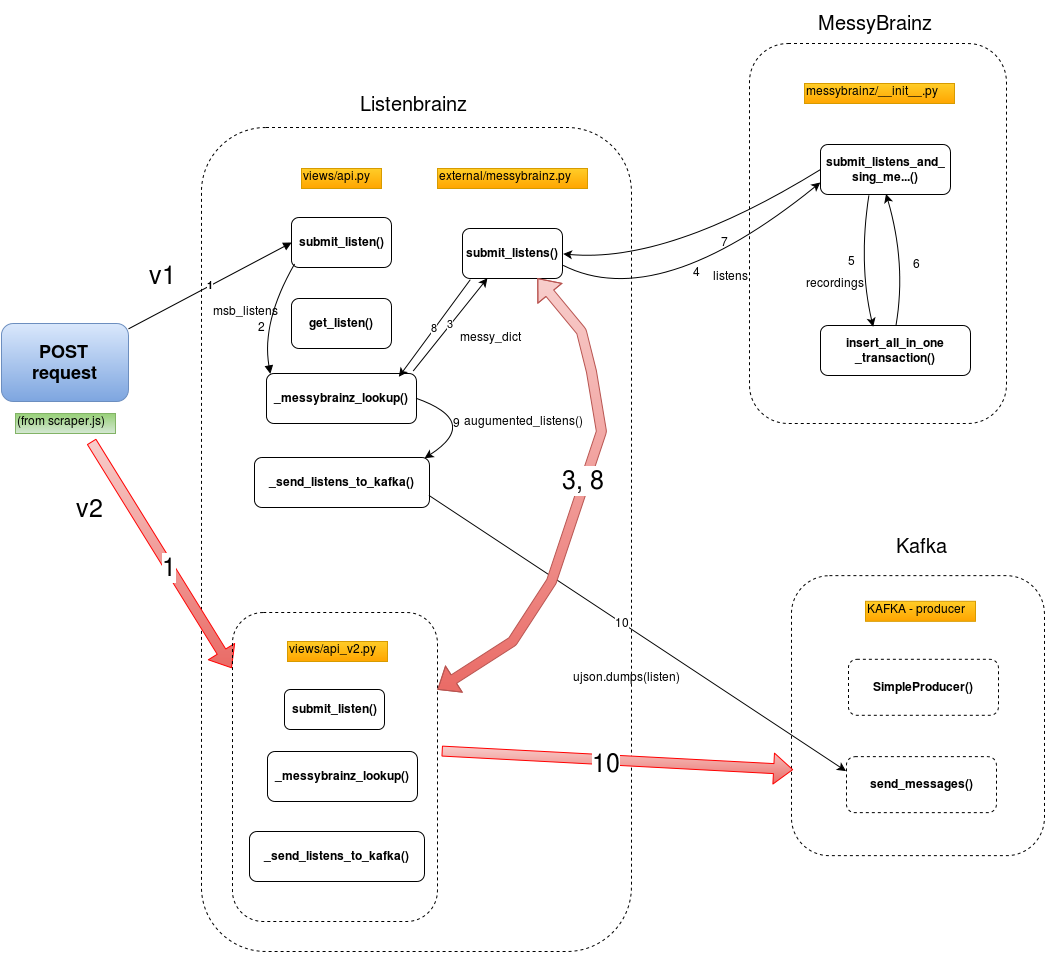
The new addition for api would process the input, validate it and then submit the appropriate messy_dict to external/messybrainz.py for furthur processing. This would use the existing infrastructure as base and provide users with a completely new API(new as in for LB).
The use of api_compat (just a name. ![]() ) will require the use of token to prevent misuse of service. Since the token is already provided to the user, the same can be used for all the write api calls. The GET calls still can be used without specifying any token.
) will require the use of token to prevent misuse of service. Since the token is already provided to the user, the same can be used for all the write api calls. The GET calls still can be used without specifying any token.
I will implement at least 2 types of auth. Desktop auth is for sure. The other auth can be web-auth or mobile-auth. (I am biased towards implementing web-auth). Surely, if time permits then i will go for all three modes of authentication.
Some part of the
compatibleAPI is already implemented and resides at GitHub - Jonty/scrobbleproxy: A Last.fm API 2.0 implementation that you do not want to use yet.
I can reuse the modules and we dont’t need to duplicate work. Ti\his would give me more time to work on integrating it with LB.
Methods to implement:
Scrobble Types supported:
- Scrobble now listening
- Scrobble tracks
The following are methods that i will implement, in descending order of priority.
| Method | Description | Documentation |
| track.scrobble | Scrobble tracks to listenbrainz.org in single or batch mode | http://www.last.fm/api/show/track.scrobble |
| track.updateNowPlaying | Update the now playing details to LB | http://www.last.fm/api/show/track.updateNowPlaying |
| XMLtoJSON | Convert a given XML response to JSON using the specified rules. | (Explained below) |
| track.getInfo | Get full metadata about a particular using using mbid or artist and track name. | http://www.last.fm/api/show/track.getInfo |
-
For each method, the lastfm documentation states the sample response type and the required arguments in more detail.
-
Appropriate verification and validation of the inputs received will be implemented to ensure security of the system.
If time permits then i will work on the optional ideas and implement them after seeking approval from mentors.
Error codes
The error codes also need to be consistent across the api. The list of all the error codes to use as documented at http://www.last.fm/api/errorcodes
More Details
-
Since lastfm uses both json and xml type responses, so the api_v2 must also support XML style responses in addition to JSON to ensure its compatibility and consistency with the rest of the Last.fm web services. Example XML response,
<similartracks track="Believe" artist="Cher"> <track> <name>Ray of Light</name> <mbid/> <match>10.95</match> <url>http://www.last.fm/music/Madonna/_/Ray+of+Light</url> <streamable fulltrack="0">1</streamable> <artist> <name>Madonna</name> <mbid>79239441-bfd5-4981-a70c-55c3f15c1287</mbid> <url>http://www.last.fm/music/Madonna</url> </artist> <image size="small">http://cdn.last.fm/coverart/50x50/1934.jpg</image> <image size="medium">http://cdn.last.fm/coverart/130x130/1934.jpg</image> <image size="large">http://cdn.last.fm/coverart/130x130/1934.jpg</image> </track> ... </similartracks> -
The json format would be created from the XML using the following rules, as stated in the lastfm documentation.
- Attributes are expressed as string member values with the attribute name as key.
- Element child nodes are expressed as object members values with the node name as key.
-
Text child nodes are expressed as string values, unless the element also contains attributes, in which case the text node is expressed as a string member value with the key #text. *
- Repeated child nodes will be grouped as an array member with the shared node name as key.
-
JSON errors are simple, and do not follow the above rule. Example,
{ "error": 10, "message": "Invalid API Key" } -
All requests will be POST, with form urlencoded (using utf-8) parameters in the body of the request.
TimeLine
Community Bonding Period (April-22 – May-22)
Study the ListenBrainz codebase. Understand the interaction between listenstore, cassandra and kafka and get a understanding of how the data is inserted in PostgreSQL and Cassandra.
Try to precisely define what all I have to code during the coding period. (I plan on submitting this before the start of the coding period. This way, me and my mentor, will be on the same page, in terms of design choice. This will help in eliminating bad design choice early enough, before it is too late)
List out the exact methods to implement in the comming period and
Solve some more random bugs, this will help in increasing interaction with mentors and the people associated with ListenBrainz, and also increase my knowledge about Cassandra and LB.
Quarter Term (May-19 – June 9)
Start Coding. By the end of this period I want to get a simple version of API working and wan to be able to run it live.(though it may miss some features).
Mid Term (June-9 – June-28)
Implement all the missing features. Write tests to check all the implemented features. 1st review from mentors.
Three Quarter Term (June-28 – July-21)
Start posting the proof-of-work application. Write some more test suite to ensure proper working of the API. Finish the main API and start working on more features, may be brainstorm on the optional ideas.
Pencils Down Date (July-21 – August-5)
Complete the coding part. Recheck the code and re-factor (if needed). Check for bugs. Write documentation.
Final Submission (August-16 – August-24)
Begin submitting the final code after long coding period. A big relief !!.
After Google Summer of Code (August-24 – )
Stay associated with Metabrainz. Work on other bugs. Pick some other major projects, like Picard. Be an active member of the community.
Week-by-week distribution of work
For the coding period (May-19 to August-24; 13 weeks), I have defined a more granular timeline, which will help me set short-term goals precisely, and see to it that I complete my work on time.
| Week | Work |
|---|---|
| 1 | Set up working environment and start the initial setup and planning. |
| 2 | Read the lastfm documentation and get a clear understanding of its working. |
| 3 | Start coding. Implement the main methods, track.scrobble and track.updateNowPlaying |
| 4 | Complete with the API token authentication. Continue coding. Check its working, do some tweaks and continue coding. |
| 5 | Implement missing features (extend the API to include more features if possible) Track down and eliminate bugs. Start mild testing along with coding. |
| 6 | Mid-term Submission Continue on previous week’s work |
| 7 | Consider review from mentor, do essential changes, do tweaks as required and continue coding. |
| 8 | Complete with the basic API and test its working. Start planing for the next week. If i am at a good position, then start with some optional tasks(after consulting with mentor). |
| 9 | CUSHION_WEEK - If i am lagging behind then cope up with the timeline. If not then then try implementing the optional features. |
| 10 | Complete working on the API. Look for the bugs, and resolve them. |
| 11 | Start testing API. Do some robust testing. Optimise the API. Handle bugs, if any. Work on documentation and write test suite. |
| 12 | CUSHION_WEEK - To handle delays (if any) or work on optional features. |
| 13 | Wrap up. Do some final edits. Prepare for Final Submission |
Expectations from Mentors
Listenbrainz with its quite complex codebase with use of multiple tools (like Casssandra, kafka, messybrainz, listenbrainz etc) makes it a unique challenge.
The mentors have been very supportive so far. I hope this continues.
Also I hope my mentors will pull me back up if I’m getting a little slow, or straying away from goal. I also believe code reading is a very good practice to avoid bugs, and so if my mentor is able to regularly take a look at the code which I commit, it will be wonderful. Also regular interaction increases chances of success and thus I would like to regularly bug my mentor! And, surely i am looking forward to contributing to AcousticBrainz as well.
About Me.
I am a second year undergraduate student, studying Computer Science and Engineering, at International Institute of Information Technology - Hyderabad, India. I started working on ListenBrainz a few days back, and since then i have enjoyed it. Though, Cassandra and Kafka were completely new to me, but my interest helped me in the whole learning process.
Though this will be my first major Open Source project, but i have sufficient programming experience.
Q. Tell us about the computer(s) you have available for working on your SoC project!
A. I would be using Intel i3 - 3rd Gen Laptop with 4GB RAM.
Q. When did you first start programming?
A. My first encounter with linux and related bash scripts happened when i was in 10th grade. But, my actual coding experience started in my 1st year at college.
Q. What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
A. (Listenbrainz) - The idea that the raw data which is being collected can be used to predict the pattern/listening habits for users. I am looking forward towards contributing to this project, which is of keen interest to me.
Q. Have you ever used MusicBrainz to tag your files?
A. Yeah !! And it was nice.
Q. Have you contributed to other Open Source projects? If so, which projects and can we see some of your code? If you have not contributed to open source projects, do you have other code we can look at?
A. I don’t have much history of contribution in Open Source. But, in the recent months i have started contributing in Linux Kernel, and occasionally try to fix bugs. Apart from this, i do a lot of projects in my free time. Most of the codes are hosted on github.
https://github.com/pinkeshbadjatiya.
Q. What sorts of programming projects have you done on your own time?
A. I believe in learning and exploring, and so i spend most of my free time doing variety of interesting projects. I have done projects like website development, AI bots for Ultimate-tic-tac-toe, 2D/3D games, issue trackers, Scheduler for xv6 operating system, c-shell etc. Details to all of my projects are there in my CV.
Q. How much time do you have available, and how would you plan to use it?
A. 36 hours per week. (~6 hours per day, with one-day off)
Q. Do you plan to have a job or study during the summer in conjunction with Summer of Code?
A. No. I would work as a full-time employee during my whole summers. I would be submitting a full timeline of my work distribution for the entire summer period.
This is a draft application. Any suggestions/changes/corrections are appreciated.

