Personal information
Nickname: diru
IRC nick: rohitdandamudi
GitHub: https://github.com/diru1100
Linkedin: https://in.linkedin.com/in/rohit-dandamudi-b235aa16a
Personal Website: https://diru1100.wordpress.com/
Time Zone: UTC+5:30 hours
Proposal
The idea of implementing a separate project for spam detection i.e SpamBrainz started in 2017. Since then, there has been advancement towards it by implementing a high accuracy model in Keras called Lodbrok to detect spam. However, this model hasn’t been plugged into the existing manual report system in the MusicBrainz project and the model has been entirely trained offline.
The proposed idea is to complete this integration and make spam detection automated and a thing of the past.
Main things I would focus on:
- Progress done in the area of online learning through the intended Spam Ninja system feedback on classified spams by Lodbrok.
- Also, creating a dedicated web-site for SpamBrainz documentation and setup for helping new contributors and get more traction.
In the future, the same concept can be extended to all other MeB projects.
Overview
The trained LSTM model called LodBrok has been implemented with offline batch-wise learning. The same model now must be deployed in the production server implemented as a Flask REST API which gets info from MusicBrainz.
Spam Ninja extension to review the SpamBrainz results must be done to existing trusty editor accounts. This feature can be added to certain accounts by creating and There will be 2 cron jobs running to execute it:
-
To check the new editors created since the last check and run them in the model after a certain minimum requirement is reached (like for every 100 new editors).
-
To take the feedback of Spam Ninja for online learning.
Both the checks will be automated and run every day or week.
The below diagram(Fig-1) describes the basic workflow.
This requires setting up a separate SpamBrainz tables integrated with current MusicBrainz schema to check and store the reports. This is the schema used to link spam reports and editor details(Fig-3). As one can see the editor_spam_report table will link the editor_id of editor table(Fig-4) of MusicBrainz and the spam_report table.

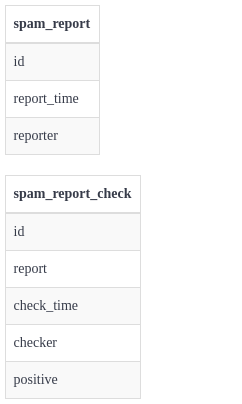
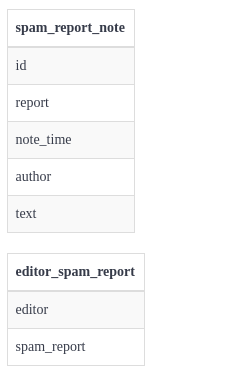
Fig-3: Spam brainz table

Fig-4: Editor table
As integrating with MusicBrainz is the end goal, the development setup of SpamBrainz will use Docker Compose (as an extension to musicbrainz-docker) and the deployment is also made through docker. Also, I have to experiment the model with incremental learning as it might show varying results taking spam ninja feedback as the classifier and tweak the model a little bit accordingly to get better results. The idea behind this is that although the accuracy might be high in batch training, the model gets baised/spoiled if it gets repeatedly given correct prediction data and vice versa during online learning. This can be reduced by actually testing the data and being aware of it’s biases before hand.
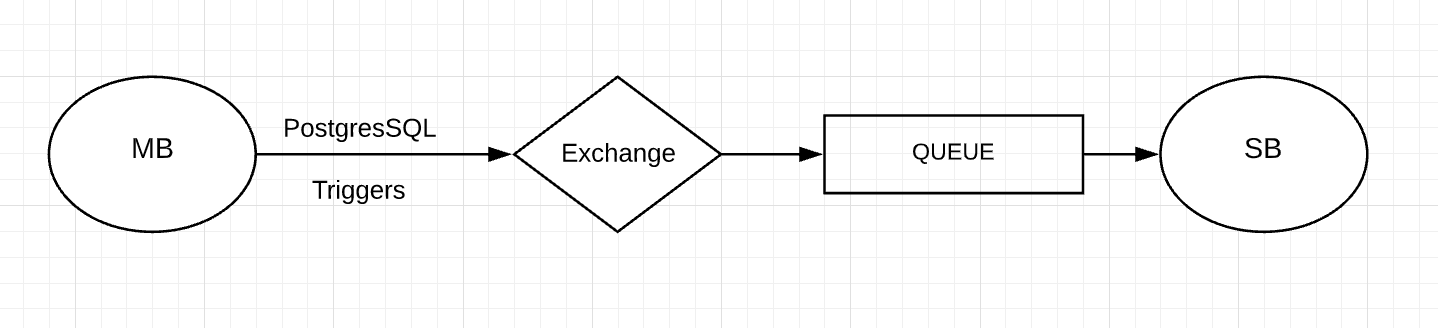
To make this work, first I will make a basic dummy site with only the editor page and give varying feedback by connecting it with SpamBrainz API. After satisfying results, the SpamBrainz production server will be integrated with MusicBrainz. One possible option to integrate will be by using PostgreSQL triggers that send messages through RabbitMQ queues and let SpamBrainz check these messages (and PostgreSQL database if needed) with cron(Fig-5). This idea is inspired from the indexed search feature which is successfully integrated with MusicBrainz. Also we have to note that the retrieved data has to be turned into a pickle file to evaluate using the current model. This can be made more generalised by using JSON data for the model, this way the data can be accessed easily from all of MeB projects when expanding in future. Final approach has to be decided after the API is built and by testing which approach is more compatible.
IMPLEMENTATION:
Lodbrok Model :
The current model covers editor spam detection, and uses pickle file to load the data and these are the layers(Fig-6) used as of now.

Using these attributes and already present spam accounts, I would like to create some dummy data to train and test the model.
SpamBrainz API:
The SpamBrainz REST API will be created in flask, the calls used for now are:
- get_new_editors() => This will get the new editors details in a certain format, for example JSON.
- get_spam_ninja_feedback() => This will get the SpamNinja binary results to train the model again thus implementing online learning.
SpamNinja Editor:
A new attribute can be added to the current editor schema, for example “role” or “account type”, which would help add the SpamNinja feature to certain trusty editor accounts. The diagram (Fig-4), shows the current editor attributes, to which role will be added. On the frontend side the user will have an extra option called “ninja mode”(Fig-6) to deal with spam.

Cron jobs and Data transmission:
Here we will use PostgreSQL triggers(Fig-7) when there are certain number of new editor accounts created and use RabbitMQ to transfer it to API. This trigger can be a cron job or on demand based on our choice.

Research bias and learn how online learning works:
This part is a continuous process and is done as I explore more and run the model with varying input test data. This site and many others explain why it’s a good thing to explore the trained model to reduce errors.
Make docs website:
This will be implemented in the same way as other MeB projects(Fig-8).

Timeline:
Community Bonding (May 4, 2020 - June 1, 2020):
Spend time testing the Lodbrok model with dummy data and document every step of it to help new contributors learn the model without breaching the privacy policy. This covers the SpamBrainz side, then I will start looking into MusicBrainz code in depth, learn various workflows, how it is all connected. So that SpamBrainz can be easily integrated with further extension in mind. This will also give me more concrete idea on what to work on in the coming weeks. Ofcourse, I already love the community and would get to know them more in this period.
Phase 1 (June 1, 2020 - June 30, 2020):
During this phase I plan to work on building the SpamBrainz API, making the model run with proper trigger functions in flask. Later, I would like to create a test site similar to editor page in MusicBrainz to test the connectivity and what type of data transmission is best (JSON, etc…). This will let me decide whether to keep training the model with current pickle file format or change it to JSON and also help me write various test functions covering all cases.
Phase 2 (June 30, 2020 - July 27, 2020):
I will proceed with implementing the SpamNinja part and integrating it with the API. To do that, I have to create the docker compose setup and deploy the API using docker. The cron job automated checks will also be done in this phase.
Phase 3 (July 28, 2020 - August 31, 2020):
In the last phase, I would like to explore various biases that the model may obtain due to online learning and how it varies over time. Also I would like to create a simple documentation website here which refers to the trained models and how everything is connected.
Weekly division of the work to be done in GSoC period:
- Week 1-2: Build SpamBrianz API and run the model with flask function calls
- Week 3-4: Create a test site to test API, write test functions and learn best data format needed(JSON, Pickle).
- Week 5-6: Implement SpamNinja and integrate with API
- Week 7-8: Docker-compose the API and deploy it, make cron job automated checks.
- Week 9-10: Research on biases acquired during online learning and make changes in model classifier, weightage given etc.
- Week 11-12: Create a documentation web-site explaining everything done so far.
- Week 13: Buffer period
STRETCH GOALS:
- Implement in other MeB sites or at least add extra modules to connect to them.
- Work on new model from scratch !!
- Moving to online options if possible (aws, azure etc)
AFTER GSOC:
Continue working with SpamBrainz and start working on the stretch goals. Also would love to make it as mainstream as other MeB projects with bunch of ML and web development enthusiasts collaborating.
Detailed information about me:
I am Dandamudi Rohit and am currently doing my junior year in Computer Science and Engineering at Chaitanya Bharathi Institute of Technology, Hyderabad, India . I’m excited to be part of the community and start contributing.
Q: Tell us about the computer(s) you have available for working on your SoC project!
A: I will use my MacBook Pro, (Core i5 Processor, 8GB RAM) running macOS Mojave and/or DELL Laptop(Core i5 Processor, 8GB RAM) running Ubuntu 18.04 LTS…
Q: When did you first start programming?
A: I started programming during 8th standard with QBasic, but learned real programming concepts and application development in High school.
Q: What type of music do you listen to? (Please list a series of MBIDs as examples.)
A: I like pop music and also listen to various songs in different languages like K-pop and Japanese music.
Some of the artists I like:The Weeknd, Juice WRLD and Bruno Mars.
Fav songs: Uptown funk, StarBoy and Boombayah
Q: What aspects of the project you’re applying for (e.g., MusicBrainz, SpamBrainz, etc.) interest you the most?
A: I like web applications a lot in general, particularly what I like about MusicBrainz is the tech stack used to maintain large amounts of data seamlessly as well as being able to maintain music records in a transparent platform.
Coming to SpamBrainz, I’m interested in the languages and frameworks that the project will be coded in, gaining experience in them would be a huge opportunity for me to learn and grow. It also has the perfect blend of machine learning and web development, which is something I always wanted to work on.
Q: Have you contributed to other Open Source projects? If so, which projects and can we see some of your code? If you have not contributed to open source projects, do you have other code we can look at?
A: I have made some major contributions to FOSSASIA and also did some basic fixes to Macports as well, both are web-development projects in Python, Here are some of my contributions:
Basic Contributions:
Major contribution:
Q: What sorts of programming projects have you done on your own time?
A: I like to explore different technologies in my free time, mostly inclined towards web-development as I believe the future is Web. Like: Map-based web application using Leaflet js, and basic web-app using MongoDB, Express, Angular, Node (MEAN) stack. Coming to python I’ve used Flask and Django also played around with Data Science libraries like Matplotlib, Pandas and have explored machine learning concepts in Tensorflow. I also successfully published research papers in the domain of data mining and its use cases.
Q: How much time do you have available, and how would you plan to use it?
A: I will be able to dedicate most of the evenings during working days and all weekends, keeping in mind that I might be having college during summer due to the ongoing pandemic, I still should be able to spend at least 40 hours a week.
 , this is my idea to implement Spam detection with online learning, please feel free to comment your views. Any feedback would be constructive.
, this is my idea to implement Spam detection with online learning, please feel free to comment your views. Any feedback would be constructive.