Personal information
Nickname: abhisheksingh
IRC nick: kanha
Email: abhishekkumarsingh.cse@gmail.com, abhishek.singh@research.iiit.ac.in
GitHub: AbhishekKumarSingh (Abhishek Singh) · GitHub
Bitbucket: Bitbucket
Blog URL: http://abhisheksingh01.wordpress.com/
Alternate Link for this proposal: Abhishek/metabrainz GSoC2016Proposal - MozillaWiki
Proposal
AcousticBrainz
Abstract
Implementation of an audio search system for AcousticBrainz. An Audio Information Retrieval(AIR) system that would provide client API(s) for audio search and information retrieval. Search will be based on annotated text/descriptions or tags/labels associated with an audio as well as on low and high level features. Focus is to implement an AIR system that provides text based and content based search. Users would be able to perform query through the provided client API(s) and will get list of relevant audios ids in return.
Benefit to AcousticBrainz community
“Search, and you will find”- Provides client API(s) for text and content based search. Query can be done by providing some text or by submitting a piece of audio.
- Support for advanced queries combining content analysis features and other metadata (tags, etc) including filters and group-by options.
- Support for duplication detection. It helps in finding duplicate entries in the collection.
- Helps in finding relevant audios quickly and efficiently.
Project Details
**INTRODUCTION**The idea is to implement a search functionality for AcousticBrainz. This would include implementing an Audio Information Retrieval System(AIRS) which would provide audio content search. This would also simplifies the task of data exploration and investigating content based similarity.
Audio Information Retrieval(AIR) can be:
- Text based
- Content based
Text based AIR :
Query can be any text say ‘rock’ or ‘beethoven’ etc and the system will search through the text(tags, artist name, description) associated with the audios and will return list of relevant audios corresponding to matched text. It’s simple to implement but doesn’t help much in audio retrieval as most of the times the audio doesn’t contains enough annotations.
Content based AIR :
It bridges the semantic gap when text annotations are nonexistent or incomplete. For example, if one comes to a record store and one only know a tune from a song or an album one want to buy, but not title of music, album, composer, or artist. It is difficult problem to solve for one. On the other hand, sales expertise with vast knowledge of the music can identify tunes hummed by one. Content based audio information retrieval can substitute the vast experience of sales expertise with a vast knowledge of the music.
Benefits
- Given a piece of audio as a query, Content based AIRS will search through the indexed database of audios return list of audios that are similar to a piece of audio given as query.
- Can detect (duplicates) copy right issues with little tweak.
REQUIREMENTS DURING DEVELOPMENT
Hardware Requirements :
- A modern PC/Laptop
- Graphical Processing Unit(GPU)
Software Requirements :
- Gaia
- Elastic search (storage database)
- elastic-py library
- Kibana (data visualization)
- Python 2.7.x/C
- Scikit, Keras
- Coverage
- Pep8
- Pyflakes
- Vim (IDE)
- Sphinx (documentation)
- Python Unit-testing framework (Unittest/Nosetest)
- AcousticBrainz tools
THE OUTLINE OF WORK PLAN
Audio information retrieval framework consists of some basic processing steps:
- Feature extraction
- Segmentation
- Storing feature vectors(indexing)
- Similarity matching
- Returning similar results
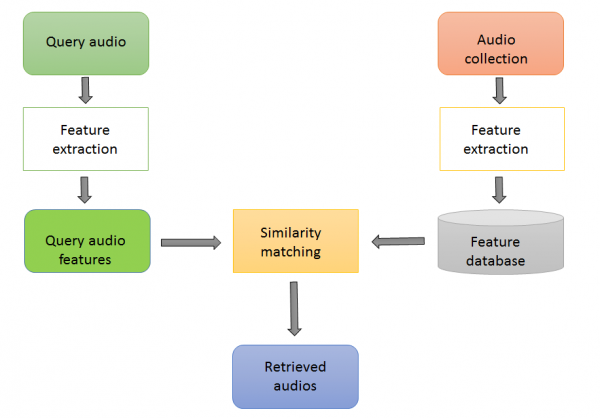
Basic flow in audio information retrieval system
Some proposed models for Content based audio retrieval
- Vector Space Model(VSM)
- Spectrum analysis(Fingerprint) model
- Deep Neural network model (Deep learning approach)
Division of Work
Basically, The whole work is divided into four phases :
- Phase I : Getting Features and index creation
- Phase II : Explore and Search Data
- Phase III : Creating Visualization model
- Phase IV : Vector Space Model
Phase I : Getting Features and index creation
Getting features via AcousticBrainz and index creation for extracted features will be done in this phase. AcousticBrainz has a lot of annotated data, including all of the information in MusicBrainz, which we can be accessed via the MusicBrainz IDs which are used in both projects, and also the generated annotation data. These features could be annotated texts, tags, descriptions, labels etc. It would also include low level and high level metadata.
These data comes from the following sources:
- Data from the lowlevel submission files
- Data from the highlevel files
- Data from MusicBrainz
Some specific list of descriptors that would be a good idea to include in a search index:
Data from the lowlevel submission files
- bpm - could be used for finding songs with specific bpm. Also, can be used in making groups.
- key - get songs or music based on key. Can be useful for some musician users.
- pitch - users(researchers) may search for sounds with specific pitch.
- tempo - used for searching. some user likes songs with hight tempo while other with low.
- length - search by total length or duration of a music. Can be useful in identifying duplicates (will be discussed later)
- type of file - search by file type. get mp3 format of some track. Helpful in serving field queries
Data from the highlevel files
- mood - searching songs based on mood. Get songs which have ‘sad’ or happy ‘mood’
- genre - search songs based on genre. ‘rock’, ‘classic’ etc.
Data from MusicBrainz
- language - get all ‘english’ songs
- release - get songs based on release info, date etc.
- track name - get music based on name. say ‘scuse me’
- gender - get songs sung by male/female singer
- speech/non speech - can be useful for grouping.
- artist - user can search for a song/music based on artist name
- instrumentation - searching songs based on instrument type. Say ‘guitar’
We do have metadata in tags in the submissions, many of the tags are of bad quality. However, we have musicbrainz recording id for each submission. Which will be used to perform a lookup on MusicBrainz to
obtain more accurate data, and add this data to the index. If we have these features then it would simplify many searching and grouping tasks. It would also help in data exploration task. It would be able to support search for a track by its name, or even search for a release or artist to add all matching recordings to a class. search could also match recordings which match certain tags. For example, there are tags on recordings in MusicBrainz which look like genres. Would we be able to say “find all recordings tagged with ‘rock’
and add them to the rock class in our genre dataset”.
[[freesound.org|Freesound]] seems to be good platform for downloading and creating datasets. They also provides annotated data and low level and high level descriptors along with videos. These features could be used in building and testing our search system.
A demo code for previewing audio from freesound.

Features retrieved form AcousticBrainz server will be stored. These features will be indexed in the elastic search database.
A sample code to store indexes in elastic search

Once we have created indexes and stored in elastic search database, search based on texts can easily be done as elastic search support Lucene based search.
Some more functionalities which elastic search provides:
- Distributed, scalable, and highly available
- Real-time search and analytics capabilities
- Sophisticated RESTful API
Hence, using elastic search for storing index is a good choice. Data stored in the elastic search will further be used to create different visualization using Kibana in the later phase.
Phase II : Explore and Search Data
After the index creation, this phase focus will be on on exploring and searching the data. This way we can evaluate and get to know the behavior of infrastructure components by analyzing the result at each step of component building. An interface to let people choose a descriptor and choose a value. Searching for this value can show a list of matching recordings. They could also do text based search through the interface. Search like get all queries matching tag ‘rock’ etc could be done.
A sample code showing an estimate of the the API(s) to be built.
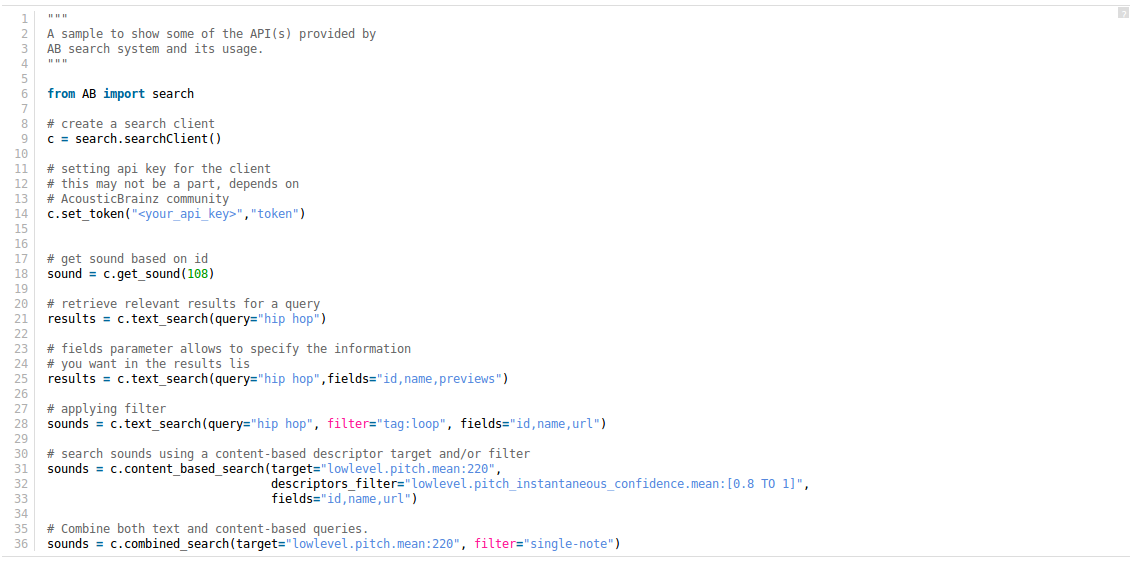
After the end of this phase search system would be able to provide some simple search results through the API(s) as mentioned above.
Phase III : Creating Visualization Model
Under this phase focus is on exploring more about the audio representations by visualization. Once, the search model is implemented. The features which lies in the vector space model will allow us to explore questions like which kind of genres do we have in the collection, what is the distribution on mood, finding link between low level data and high level data.
It comes very handy to understand the behavior of data once we visualize it. For the purpose of visualization Kibana will be used.
Reason for using Kibana
Kibana provides the following functionality:
- Flexible analytics and visualization platform
- Real-time summary and charting of streaming data
- Intuitive interface for a variety of users
- Instant sharing and embedding of dashboards
An interface showing graphs, While kibana can be of good use, we should also do some investigation to see if this is in fact necessary. If we can do the same by running some simple ES search queries then Kibana wouldn’t be necessary.
Phase IV : Vector Space Model(VSM)
This is a basic yet effective model. The idea is to represent every audio entity in vector form in the feature space.
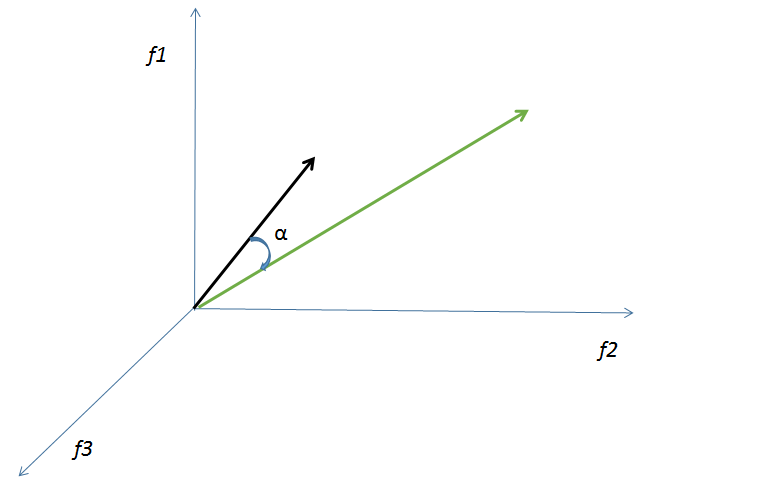
Vector space representation in 3D
Given a query audio, learn the vector representation of it and then find the similarity between the query vector and indexed audio vectors. More the similarity more is its relevance. Cosine similarity measure can be used to calculate relevance score. Features for audio could be tempo, bpm, average volume, genre, mood, fingerprint etc. Hybrid features that is features from high level, low level and meta data will be combined to represent vector space. Each audio will have their representation in this space. Since, it's a high level space we should use PCA to reduce the dimensionality and project it in low dimensional space. Now, in this low dimensional space, similarity measures will be calculated.
This could be done by using Gaia software already present.
Nice to have : Deep Neural Network Model (Deep learning Approach)
While this will not be in the scope of summer of code but, would be nice to explore afterwards. This method helps in learning features of a audio automatically. It’s an unsupervised approach to learn important features. In deep neural network each layer extracts some abstract representation of the audio. The idea is through each computation layer the system is able to learn some representation of the audio. Initial sets of inputs is passed through the input layer and computations are done at the hidden layers. After passing some hidden layer we learn new feature representation of initial input features. These new learned features vectors will be the representations of audios. Now, we could use machine learning algorithm on these features to do various classification and clustering job. This would help in dataset building and model set creation.

In feature space, the audio will be close to each other have some kind of similarity notion between them.
Advantage
- Saves the effort of learning features of audio (meta data extraction and manual labeling).
- It can be used to find similar audios/music. Which can be useful in content based search and by using user information it can be used to recommend songs/audios.
- It can be used to detect duplicate songs. It generally happens that two songs ends up having different Ids but are indeed same songs.
Deliverables
An Audio retrieval system that supports following features- Client API(s) for searching.
- Support for text based search. User can search relevant audios by providing tag/label or some keywords.
- Support for content based search. It will show similar audios based on content provided by user. Query can be done by providing a piece of audio also.
- Fingerprinting and similarity features will help in duplication detection.
- Support for advanced queries. User would be able to filter and group results.
- Visualization support for the data powered by Kibana.
- Proper documentation on the work for users and developers.
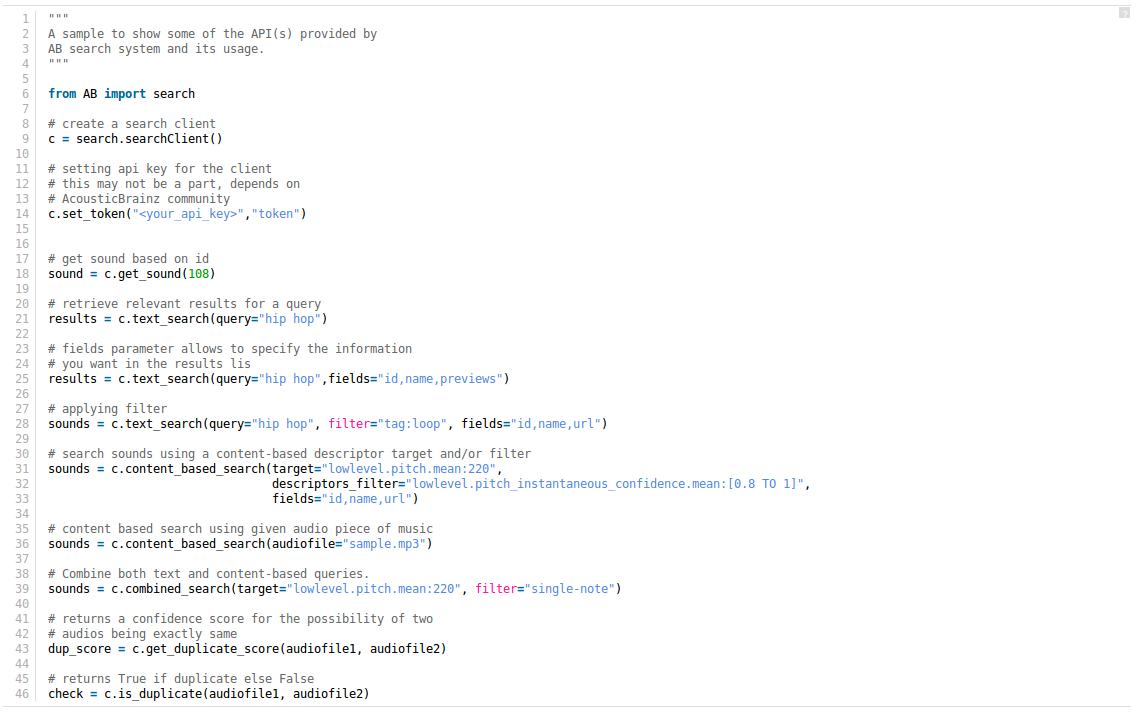
A sample code showing an estimate of the the API(s) provided at the end.
Project Schedule
-
Requirements gathering…1 week
-
Writing down requirements of the user.
-
Setting up test standards.
-
Writing test specification to test deployed product.
-
Start writing developer documentation.
-
Learn more about elastic search and kibana, Gaia
-
Getting features and Indexing…3 weeks
-
Getting features to work on.
-
Writing code to extract/retrieve features from the server.
-
Writing automated unit test to test written code.
-
Adding to developer documentation.
-
Explore and Search Data…3 weeks
-
Writing code to explore and visualize data.
-
Implementation of basic search API(s)
-
Writing automated unit test to test written code
-
Adding to developer documentation.
-
Creating visualization Model…2 week
-
Writing code for data visualization.
-
Writing automated unit test to test written code.
-
Adding to findings to documentation.
-
Implement Vector Space model…2 weeks
-
Implement similarity measure
-
Comparing VSM model with the Gaia model.
-
Adding details to documentation
-
Buffer Time…1 week
-
Prepare user documentation.
-
Implement nice-to-have features.
-
Improve code readability and documentation.
Task to be done before midterm [23rd May, 2016 - 23th June, 2016]
- Requirements gathering
- Getting features and indexing
- Start work on explore and search data
Task to be done after midterm [25th June, 2016 - 20th August, 2016] - Exploring and Searching data
- Creation of Visualization Model
- Buffer Time
Detailed information about myself
-
Tell us about the computer(s) you have available for working on your SoC project!
Hardware availability: Dell XPS l502X, 8 gb ram, 2 gb nvidia graphics card, intel i7 processor -
When did you first start programming?
I started programming when I was in 8th standard at school. -
What type of music do you listen to? (Please list a series of MBIDs as examples.)
I like romantic songs, intrumental music. Some series of MBIDs of songs or artist I like are: ed3f4831-e3e0-4dc0-9381-f5649e9df221, 5f776470-d6b9-41b7-905e-09c72352eeb7, 3f2514eb-212f-44f6-b528-78a3aafa0db4, 0f342f00-5bdc-4f5b-ab9a-761090896f1c, 93622908-0806-4173-94c1-9e42597af01 -
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
I am interested in AcousticBrainz project. I am a research scholar interested in the field of information retrieval. AcousticBrainz ease the process for researcher by providing preprocessed extracted features. Extracting different features is no longer a problem for researchers. Further it gives a vast data store coming with varied sources and make information access easier.
Time
I will be spending 45 hours per week for this project.Summer Plans
I am a first year masters student and my final exams will be over by the end of April, 2016. Then we have summer vacation till end of July. As, I am free till then so, I will be spending much of my time towards my project.
Motivation
I am a kind of person who always aspires to learn more and explore different areas. I am also an open source enthusiast who likes exploring new technologies. GSoC(Google Summer of Code) provides a very good platform for students like me to learn and show case their talents by coming up with some cool application at the end of summer. I am research scholar with interest in information retrieval. This project would help me in getting my hands dirty in AIR field and would provide me with the base to do research in this field with global community interaction and support.
Bio
I am a first year MS in Computer Science and Engineering student at IIIT Hyderabad, India. I am passionate about machine learning, deep learning, information retrieval and text processing and have keen interest in Open Source Software. I am also a research assistant at Search and Information Extraction Lab (SIEL) at my university.
Experiences
My work includes information retrieval for text based systems. During my course work I created a search engine on whole Wikipedia corpus from scratch. I have also been using machine learning and have dived into deep learning concepts for representation learning. Currently, I am working on learning efficient representations of nodes in social network graph.
I have sound knowledge of programming language namely Python, Cython, C, C++ etc. I have good understanding of python's advanced concepts like descriptors, decorators, meta-classes, generators and iterators along with other OOPs concepts. Also, I have contributed to some of the open source organizations like Mozilla, Fedora, Tor, Ubuntu before. As a part of GSoc 2014 project I worked for the Mars exploration project of Italian Mars Society. It was a virtual reality project where I implemented a system for full body and hand gesture tracking of astronauts. This allows astronauts in real world to control their avatar in virtual world through their body gestures. Details of this project can be found at:
concept idea : Abhishek/IMS Gsoc2014Proposal - MozillaWiki
IMS repo : Bitbucket
Details of some of my contributions can be found here Abhishek/contributions - MozillaWiki
My CV : https://github.com/AbhishekKumarSingh/CV/blob/master/abhishek.pdf
 )
)