I just ran your code, and it worked for me. As I had not fully implemented things it gave a 401 error response for acousticbrainz.org, and called the callback with the error set. When I instead called a local stub that always succeeded I got a success response.
Just to double check: Does the callback work when you use a webservice.get instead? And you are calling this from a running Picard? Because the Qt networking needs a running event loop.
Weird. It works just fine with get. The post only prints the POST-DATA message, while the request itself doesn’t seem to be ever called. Update: the post is sent and I’ve received the response while testing the build from Actions. I suspect there is an issue with my dependencies version on Anaconda Python.
Yes, its running from Picard, after the networking stack have already matched the album, fetched the cover, checked if the recording ID already has an AB features submission. I’m confused.
Selecting, extracting and submitting should be fine now. Unless I’ve sent something wrong… But never heard back from AB people, so I’m assuming everything is working as it should.
Also, arbitrarily set the number of worker threads to number of threads-2 not to bog down the entire computer. Maybe we should also check RAM, as some extractor instances reached up to 170MB while testing my ~10MB MP3/AAC files. Not sure how memory consumption scales with file sizes and may be a problem for some computers.
Still have no idea how to show progress (statusbar assumes fast file operations but extraction is a slowpoke) and visually display what happened (so far, everything only gets logged). Tried some stuff, but didn’t like it.
I am really bad with UI stuff, so I accept suggestions and help with that
P.S.: I didn’t write the registry/whatever to keep track of what have been sent yet.
Still have no idea how to show progress (statusbar assumes fast file operations but extraction is a slowpoke) and visually display what happened (so far, everything only gets logged). Tried some stuff, but didn’t like it.
Maybe two things that give an ETA? One that says how long until the current song is done, and one that says how long until it’s done with the album(s) being scanned?
I was thinking of revamping the statusindicator and provide a general ETA.
Instead of weighting the percentages of network and file operations, I wanted to track them over time and based on that estimate the time to end.
Here is a proof-of-concept
from functools import partial
prev_file_pending = 0
prev_network_pending = 0
prev_time = 0
prev_eta = 0
from random import randint
import time
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor()
def statusindicator():
global prev_time
pending_network = current_network_tasks - done_network_tasks
pending_file = current_file_tasks - done_file_tasks
# If there is no pending job, we keep updating the starting time of the estimate
# This also resets estimates for future jobs
if (pending_file + pending_network) == 0:
prev_time = time.time()
current_time = time.time()
# Estimate ETA
if (done_file_tasks+done_network_tasks) > 1:
total_jobs = current_network_tasks+current_file_tasks
done_jobs = done_network_tasks+done_file_tasks
eta_seconds = (current_time-prev_time) / (done_jobs)* (total_jobs-done_jobs)
seconds = max(eta_seconds, 0)
days = int(seconds/86400)
seconds = seconds - days*86400
hours = int(seconds/3600)
seconds = seconds - hours*3600
minutes = int(seconds/60)
seconds = seconds - minutes*60
estimated_remaining_time = ("%.dd:%dh:%dm:%ds" % (days, hours, minutes, seconds))
print(estimated_remaining_time)
del seconds, minutes, hours, days
current_file_tasks = 0
current_network_tasks = 0
done_file_tasks = 0
done_network_tasks = 0
def task(sleeptime):
time.sleep(sleeptime)
def count_done(file_task, callback, future):
global done_file_tasks, done_network_tasks
done_file_tasks += file_task
done_network_tasks += not file_task
callback()
def main():
global current_file_tasks, current_network_tasks, done_network_tasks, done_file_tasks, prev_time
prev_time = time.time()
rand_intervals = [randint(5,10) for _ in range(20)] + [randint(50,100) for _ in range(20)] + [randint(5,10) for _ in range(60)]
for _ in range(100):
file_task = randint(0,2)
current_file_tasks += file_task
current_network_tasks += not file_task
task_result = pool.submit(task, rand_intervals[_])
task_result.add_done_callback(partial(count_done, file_task, partial(statusindicator)))
while done_network_tasks != current_network_tasks and done_file_tasks != current_file_tasks:
time.sleep(10)
print()
main()
Do you people prefer an upper bound ETA (where whatever task you’re doing will hardly take more time than initially estimated) or adjusting over time (where it can slowly creep up, and up, and up, and then the thing you thought was ending now still needs 20h)?
Here is the upper bound ETA version (the freeze+jump in 2:20 is clicking to scan 18k files)
Update 3: Apparently I can’t keep answering the same post consecutively with updates.
Functionality-wise, I think everything is pretty much done.
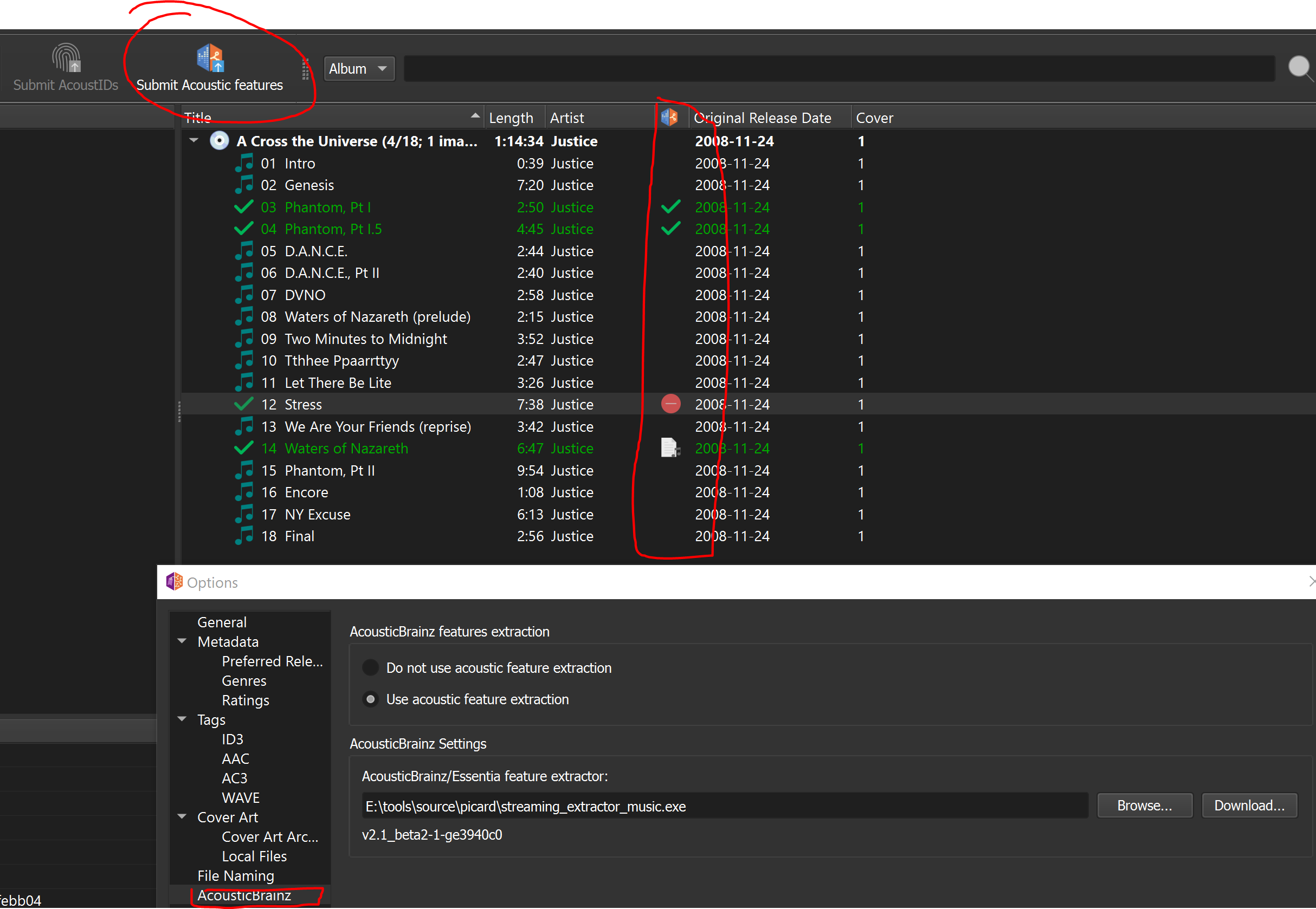
UI settings to enable the thing, locate the extractor/redirect to the download site, put the toolbar button, a column to indicate the status: pending, succeeded (checked for duplicate and, if not a duplicate, extraction+submission) or failed (extraction or submission).
How can I configure the number of simultaneous streaming_extractor_music.exe processes to be started by Picard? On my 4 core / 8 thread CPU machine there are 12 processes started and that’s using quite a lot of CPU. I would like to limit the number of processes to 4 so I can continue to work normally while features extraction is in progress.